來源:有新Newin
5 月15 日凌晨,Google I/O 開發者大會正式召開,以下是長達2 小時發表會內容摘要:
1. 關於Gemini
1)Gmail 中的Gemini
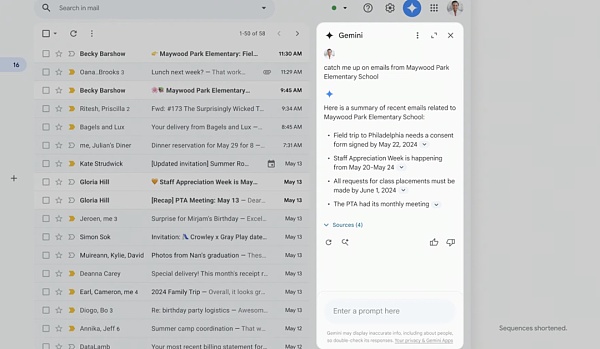
Gmail 用戶將能夠使用Gemini AI 技術搜尋、總結和起草電子郵件。它還能夠對電子郵件採取行動以執行更複雜的任務,例如透過搜尋收件匣、尋找收據和填寫線上表單來幫助你處理電商退貨。
2)Gemini 1.5 Pro & Flash

另一個升級是Gemini 現在可以分析比以前更長的文件、程式碼庫、視訊和音訊記錄。谷歌目前的旗艦機型Gemini 1.5 Pro 新版本的私人預覽中,據透露,它最多可容納200 萬token。這是之前的兩倍,新版Gemini 1.5 Pro支援所有商用型號中最大的輸入。

對於要求較低的應用,Google推出了公共預覽版Gemini 1.5 Flash,這是Gemini 1.5 Pro 的「精煉」版本,是專為「窄」、「高頻」生成AI 工作負載而構建的小型高效模型。 Flash 擁有多達200 萬個token 上下文窗口,與Gemini 1.5 Pro 一樣是多模式的,這意味著它可以分析音訊、視訊和圖像以及文字。
此外,超過150 個國家和超過35 種語言的Gemini Advanced 用戶可以利用Gemini 1.5 Pro 的更大上下文,讓聊天機器人分析、總結和回答有關長文件(最多1,500 頁)的問題。
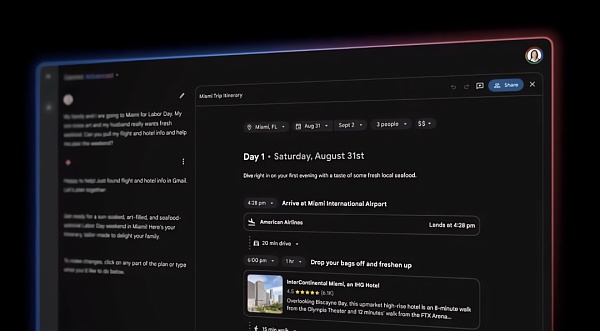
Gemini Advanced 用戶可以從今天開始與Gemini 1.5 Pro 進行交互,還可以從Google Drive 匯入文件或直接從行動裝置上傳文件。
在接下來的幾個月中,Gemini Advanced 將獲得一種新的“規劃體驗”,可根據提示建立自訂旅行行程。考慮到飛行時間(來自用戶Gmail 收件匣中的電子郵件)、膳食偏好和當地景點資訊(來自Google 搜尋和地圖資料)以及這些景點之間的距離等因素,Gemini 將產生自動更新的行程以反映任何變化。
在不久的將來,Gemini Advanced 用戶將能夠創建Gems,這是由Google Gemini 模型提供支援的自訂聊天機器人。沿著OpenAI 的GPT 的思路,Gems 可以從自然語言描述生成- 例如,“你是我的跑步教練。給我一個每日跑步計劃”——並與他人分享或保密。
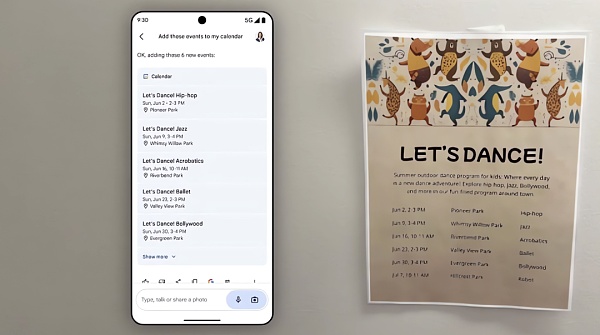
很快,Gems 和Gemini 將能夠利用與Google 服務的擴展集成,包括Google 日曆、任務、Keep 和YouTube Music,以完成各種省力任務。
3)Gemini Live
谷歌預覽了Gemini 中名為Gemini Live 的新體驗,它可以讓用戶在智慧型手機上與Gemini 進行「深入」的語音聊天。
用戶可以在聊天機器人說話時打斷Gemini,提出澄清問題,它會即時適應他們的語音模式。 Gemini 可以透過智慧型手機相機拍攝的照片或影片來查看用戶的周圍環境並對其做出反應。
谷歌表示,它利用生成式AI 新技術來提供卓越的、不易出錯的圖像分析,並將這些技術與增強的語音引擎相結合,以實現更一致、情感表達和現實的多輪對話。
從某種程度上來說,Gemini Live 是Google Lens(Google長期用於分析影像和影片的電腦視覺平台)和Google Assistant(Google跨手機、智慧音箱和電視的人工智慧驅動、語音生成和識別虛擬助理)的演變。
DeepMind 首席科學家Oriol Vinyals 表示,這是一個即時語音介面,具有極其強大的多模式功能和長上下文。
推動Live 的技術創新部分源自於Project Astra,這是DeepMind 內部的一項新舉措,旨在創建AI 驅動的應用和智慧體,以實現即時、多模式理解。
DeepMind CEO Demis Hassabis 表示,Google一直希望打造一款在日常生活中有用的通用智能體,想像一下代理商可以看到和聽到我們所做的事情,更好地了解我們所處的環境並在對話中快速做出反應,從而使互動的速度和品質感覺更加自然。
據悉,Gemini Live 直到今年稍後才會推出,它可以回答有關智慧型手機相機視野內(或最近視野內)事物的問題,例如用戶可能位於哪個社區或損壞的自行車上的某個部件的名稱。指向電腦程式碼的一部分,Live 可以解釋該程式碼的作用。或者,當被問及一副眼鏡可能在哪裡時,Live 可以說出它最後一次「看到」眼鏡的位置。

Live 也被設計為某種虛擬教練,幫助使用者排練活動、集思廣益等。例如,Live 可以建議在即將到來的工作或實習面試中強調哪些技能,或提供公開演講建議。
新的ChatGPT 和Gemini Live 之間的一個主要區別是Gemini Live 不是免費的。一旦推出,Live 將是Gemini Advanced 的專屬版本,Gemini Advanced 是Gemini 的更複雜版本,受Google One AI Premium Plan 保護,價格為每月20 美元。
4)Gemini Nano

谷歌也從Chrome 126 開始,將最小的AI 模型Gemini Nano 直接建置到Chrome 桌面用戶端。谷歌表示,這將使開發人員能夠使用裝置上的模型來支援自己的AI 功能。例如,Google計劃利用這項新功能來支援Gmail 中Workspace Lab 現有的「幫助我寫作」工具等功能。
 GoogleChrome 產品管理總監Jon Dahlke 指出,Google正在與其他瀏覽器供應商進行談判,以便在他們的瀏覽器中啟用此功能或類似功能。
GoogleChrome 產品管理總監Jon Dahlke 指出,Google正在與其他瀏覽器供應商進行談判,以便在他們的瀏覽器中啟用此功能或類似功能。
5)Android 上的Gemini
谷歌在Android 上的Gemini 是Google Assistant 的 AI 替代品,很快就會利用其與Android 行動作業系統和Google應用程式深度整合的能力。
用戶將能夠將 AI 生成的圖像直接拖放到他們的Gmail、Google Messages 和其他應用程式中。
谷歌表示,與此同時,YouTube 用戶將能夠點擊“詢問此影片”,從該YouTube 影片中查找特定資訊。
購買升級版Gemini Advanced的使用者還可以使用「詢問此PDF」選項,讓您無需閱讀所有頁面即可從文件中獲得答案。 Gemini Advanced 訂閱者每月支付19.99 美元即可存取AI,並獲得2TB 儲存空間以及其他Google One 福利。
谷歌表示,Android 版Gemini 的最新功能將在未來幾個月推廣到數億個支援的裝置。隨著時間的推移,Gemini 將不斷發展,提供與螢幕上的內容相關的其他建議。

同時,Android 裝置上的基礎模型Gemini Nano 將升級以包含多模態。這意味著它將能夠處理文字輸入以及其他處理資訊的方式,包括視覺、聲音和口語。
6)Google地圖上的 Gemini
從Places API 開始,Gemini 模型功能將登陸Google 地圖平台供開發者使用。開發人員可以在自己的應用程式和網站中顯示地點和區域的生成 AI 摘要。這些摘要是基於Gemini 對Google 地圖社群超過3 億貢獻者的見解分析而創建的。
這些摘要是基於Gemini 對Google 地圖社群超過3 億貢獻者的見解分析而創建的。借助這項新功能,開發人員將不再需要編寫自己的自訂地點描述。
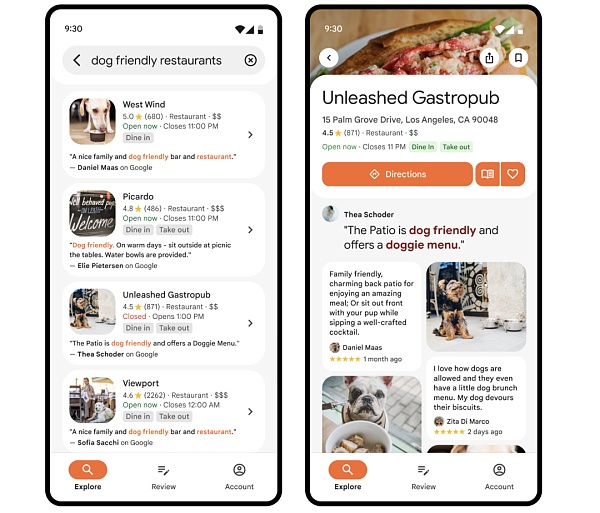
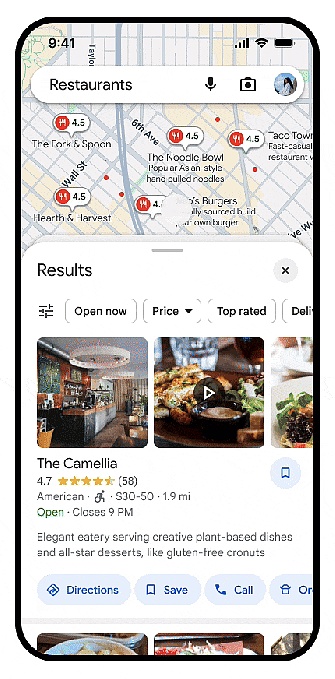
例如,如果開發人員有一個餐廳預訂應用程序,這項新功能將幫助用戶了解哪家餐廳最適合他們。當用戶在應用程式中搜尋餐廳時,他們將能夠快速查看所有最重要的信息,例如餐廳特色菜、歡樂時光優惠和餐廳氛圍。
新的摘要適用於多種類型的場所,包括餐廳、商店、超市、公園和電影院。谷歌也將AI 驅動的上下文搜尋結果引入Places API。當使用者在開發者的產品中搜尋地點時,開發者現在可以顯示與其搜尋相關的評論和照片。
7)TPU 效能提升

谷歌推出了下一代——確切地說是第六代——TPU AI 晶片。它們被稱為Trillium,將於今年稍後推出。如果你還記得的話,宣布下一代TPU 已成為I/O 大會上的傳統,儘管這些晶片僅在今年晚些時候推出。

與第五代相比,這些新型TPU 的每晶片運算效能將提高4.7 倍。 Trillium 具有第三代SparseCore,Google將其描述為「用於處理高級排名和推薦工作負載中常見的超大型嵌入的專用加速器。
Pichai 將新晶片描述為Google迄今為止「最節能」的TPU,隨著對AI 晶片的需求持續呈指數級增長,這一點尤其重要。
他表示,過去六年,業界對ML 運算的需求成長了100 萬倍,每年約成長十倍,如果不投資降低這些晶片的功耗需求,這是不可持續的。谷歌承諾,新型TPU 的能源效率比第五代晶片高出67%。

此外,Google在Gemma 2 中新增一個新的270 億參數模型。下一代GoogleGemma 模型將於6 月推出。谷歌表示,這個尺寸經過Nvidia 優化,可以在下一代GPU 上運行,並且可以在單一TPU 主機和頂點AI 上高效運行。
2. 新模型&項目
1)Imagen3
 谷歌推出了Imagen 模型的最新產品— Imagen 3。 DeepMind CEO Demis Hassabis 表示,與前身Imagen 2 相比,Imagen 3 能夠更準確地理解翻譯成圖像的文字提示,並且比前幾代產品更加富有創意和細緻。
谷歌推出了Imagen 模型的最新產品— Imagen 3。 DeepMind CEO Demis Hassabis 表示,與前身Imagen 2 相比,Imagen 3 能夠更準確地理解翻譯成圖像的文字提示,並且比前幾代產品更加富有創意和細緻。
為了減輕人們對深度偽造的可能性的擔憂,Google表示Imagen 3 將使用SynthID,這是DeepMind 開發的一種方法,可將不可見的加密浮水印應用於媒體。
谷歌的ImageFX 工具可以註冊Imagen 3 的私人預覽版,Google表示,該模型將「很快」提供給使用Google企業生成式AI 開發平台Vertex AI 的開發人員和企業客戶。
2)Veo 視訊生成模型

Google正在瞄準OpenAI 的Sora with Veo,這是一種 AI 模型,可以根據文字提示創建大約一分鐘長的1080p 影片剪輯。 Veo 可以捕捉不同的視覺和電影風格,包括風景和延時鏡頭,並對已生成的鏡頭進行編輯和調整。
它還建立在谷歌在四月份預覽的視頻生成方面的初步商業工作的基礎上,該工作利用該公司的Imagen 2 系列圖像生成模型來創建循環視頻剪輯。
Demis Hassabis 表示,Google正在探索故事板和生成更長場景等功能,以了解Veo 的功能,而Google在影片方面取得了令人難以置信的進步。

Veo 接受了大量鏡頭的訓練。這就是生成式AI 模型的工作原理:輸入某種形式資料的一個又一個範例,模型會拾取資料中的模式,使它們能夠產生新資料——在Veo 的例子中是影片。

然而,Google已經向選定的創作者提供了Veo,其中包括Donald Glover(又名Childish Gambino)和他的創意機構Gilga。
3)LearnLM 模型
谷歌推出了LearnLM,這是一個針對學習進行「微調」的新生成 AI 模型系列。這是谷歌DeepMind AI 研究部門和谷歌研究院之間的合作。谷歌表示,LearnLM 模型旨在「對話式」輔導學生一系列科目。
LearnLM 已經在Google 的多個平台上可用,並且正在透過Google Classroom 的試點計畫來使用LearnLM。谷歌表示,LearnLM 可以幫助教師發現新的想法、內容和活動,或找到適合特定學生群體需求的材料。
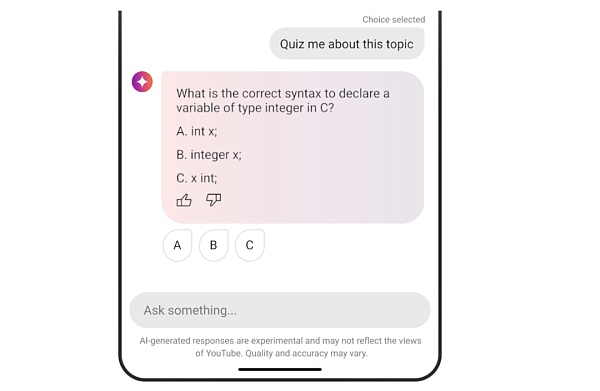
YouTube 的新功能是 AI 產生的測驗。這種新的對話式 AI 工具允許用戶在觀看教育影片時象徵性地「舉起」手。觀眾可以提出澄清問題、獲得有用的解釋或就主題進行測驗。
由於Gemini 模型的長上下文功能,這對於必須觀看較長教育影片(例如講座或研討會)的人來說會有所緩解,這些新功能正在向美國部分Android 用戶推出。
4)Project IDX
Project IDX 是Google下一代、以 AI 為中心、基於瀏覽器的開發環境,現已進入公開測試階段。

谷歌副總裁兼Developer X 總經理兼負責人Jeanine Banks 表示,隨著AI 變得越來越普遍,部署所有這些技術所帶來的複雜性確實變得越來越困難、越來越大,谷歌希望幫助解決這項挑戰。開發商關係,這就是建造 Project IDX 的原因。
IDX 是一種多平台開發體驗,可以讓建立應用程式變得快速、輕鬆,你可以透過Next.js、Astro、Flutter、Dart、Angular、Go 等易於使用的模板輕鬆使用您喜歡的框架或語言。
此外,Google 將與Google Maps Platform 的整合添加到IDE 中,協助為其應用程式添加地理定位功能,並與Chrome 開發工具和Lighthouse 整合以協助調試應用程式。很快,谷歌還將支援將應用程式部署到 Cloud Run,這是Google Cloud 的無伺服器平台,用於運行前端和後端服務。
該開發環境還將與GoogleAI 驅動的合規平台 Checks 集成,該平臺本身將於週二從測試版轉為正式版。當然,IDX 不僅僅是建立支援AI 的應用程序,它還涉及在編碼過程中使用AI。
為了實現這一點,IDX 包括許多現在已成為標準功能的功能,例如程式碼完成和聊天助理側邊欄,以及創新功能,例如突出顯示程式碼片段的功能,以及類似於Photoshop 中的生成填充功能,詢問Google的Gemini 模型更改程式碼片段。
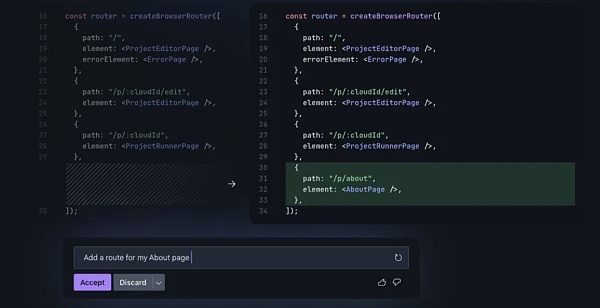
每當Gemini 建議程式碼時,它都會連結回原始來源及其相關許可證。 Project IDX 是Google 以開源Visual Studio Code 為核心構建的,它還與GitHub 集成,可以輕鬆地與現有工作流程集成。在IDX 的最新版本之一中,Google 也在IDE 中為行動開發人員添加了內建iOS 和Android 模擬器。
3. 應用程式&工具更新
1)AI 在搜尋中的應用
谷歌搜尋主管Liz Reid 表示,Google為搜尋建立了客製化的Gemini 模型,將即時資訊、Google排名、長上下文和多模態特徵結合在一起。

谷歌正在其搜尋中添加更多 AI ,緩解了人們對該公司正在將市場份額輸給ChatGPT 和Perplexity 等競爭對手的疑慮。
谷歌正在向美國用戶推出 AI 驅動的概述。此外,該公司還希望使用Gemini 作為旅行計劃等事務的智能體。
谷歌計劃使用生成式 AI 來組織某些搜尋結果的整個搜尋結果頁面。這是對現有 AI 概述功能的補充,該功能會創建一個簡短的片段,其中包含有關您正在搜尋的主題的聚合資訊。經過谷歌 AI 實驗室計劃的一段時間後, AI 概述功能將於週二全面開放。
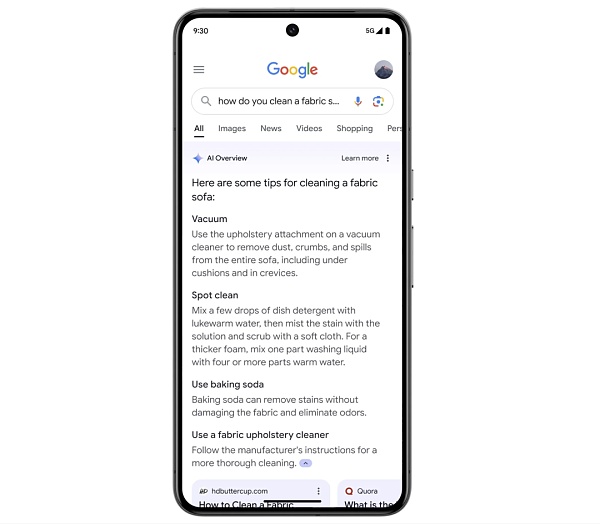
自去年以來,Google一直在透過其搜尋生成體驗(SGE)測試AI 驅動的概述。現在,它將於本週在美國向「數億用戶」推出,目標是在今年年底前向超過10 億人提供服務。
她還表示,在其AI 概述功能的測試期間,Google觀察到人們點擊了更多樣化的網站。當傳統搜尋足以提供結果時,使用者將看不到AI 概述,該功能對於比較複雜、資訊分散的查詢更有用。
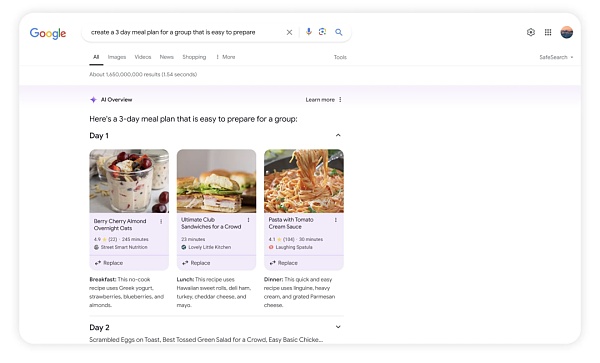
此外,Google還希望使用Gemini 作為智能體Agent 來完成膳食或旅行計劃等任務。用戶可以輸入諸如「為四口之家計劃三天的膳食」之類的查詢,並獲取這三天的連結和食譜。
2)圈選搜尋

由 AI 驅動的「圈搜尋」功能允許Android 用戶使用轉圈等手勢立即獲得答案,現在將能夠解決更複雜的心理學和數學應用題。
它的設計目的是讓用戶在手機上的任何地方都可以更自然地透過一些操作(例如圈選、突出顯示、塗鴉或點擊)來使用Google 搜尋。
3)在通話過程中偵測詐騙
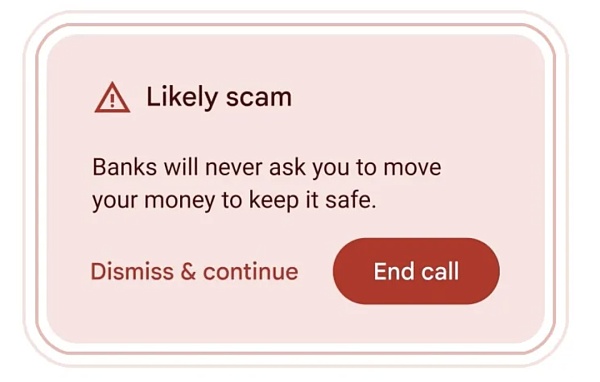
谷歌預覽了一項功能,它認為該功能將在通話過程中提醒用戶潛在的詐騙。
該功能將內建於Android 的未來版本中,它利用Gemini Nano,這是Google 生成式AI 產品的最小版本,可以完全在裝置上運行。該系統有效地即時監聽「通常與詐騙相關的對話模式」。
谷歌舉了一個假裝是「銀行代表」的例子。密碼請求和禮品卡等常見的詐騙策略也會觸發該系統。這些都是眾所周知的從你身上榨取錢財的方式,但世界上有很多人仍然容易受到此類騙局的侵害。一旦啟動,它會彈出一條通知,提示用戶可能會成為令人討厭的角色的受害者。
4)詢問照片
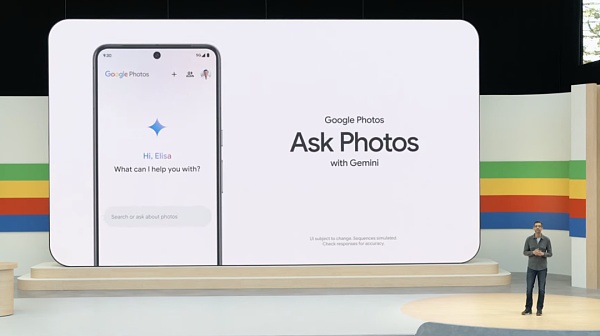
谷歌照片正在註入 AI ,推出了一項實驗性功能“Ask Photos”,該功能由Google的Gemini AI 模型提供支援。今年夏天晚些時候推出的新功能將允許用戶使用自然語言查詢來搜尋他們的Google 照片集,這些查詢利用了 AI 對其照片內容和其他元資料的理解。
雖然在用戶可以搜尋照片中的特定人物、地點或事物之前,借助自然語言處理, AI 升級將使找到正確的內容更加直觀,減少手動搜尋過程。
5)Firebase Genkit
 Firebase 平台新增了一個名為Firebase Genkit 的功能,旨在讓開發人員更輕鬆地使用JavaScript/TypeScript 建構AI 驅動的應用,並且即將推出對Go 的支援。
Firebase 平台新增了一個名為Firebase Genkit 的功能,旨在讓開發人員更輕鬆地使用JavaScript/TypeScript 建構AI 驅動的應用,並且即將推出對Go 的支援。
它是一個開源框架,使用Apache 2.0 許可證,使開發人員能夠快速將AI 建置到新的和現有的應用程式中。
此外,Google重點介紹Genkit 的一些用例,包括許多標準GenAI 用例:內容生成和摘要、文字翻譯和生成圖像。
6)Google Play
Google Play 憑藉新的應用程式發現功能、獲取用戶的新方式、Play Points 更新以及面向開發者的工具(例如Google Play SDK Console 和Play Integrity API 等)的其他增強功能而受到了一些關注。
開發人員特別感興趣的是名為Engage SDK 的東西,它將為應用程式製造商引入一種方式,以針對個人用戶的個人化全螢幕、沉浸式體驗向用戶展示其內容。不過,Google表示,用戶目前無法看到這個表面。