

作者:Nickqiao & 霧月,極客web3
今年4月,Vitalik造訪香港區塊鏈峰會,發表了題為《Reaching the Limits of Protocol Design》的演講,其中再次提到ZK-SNARKs在以太坊Danksharding路線圖中彰顯出的潛力,並展望了ASIC晶片對ZK加速的巨大幫助。
先前Scroll聯創張燁也曾指出,ZK在傳統領域的應用空間可能比Web3內的還大,可信賴運算、資料庫、可驗證性硬體、內容防偽及zkML等領域都有對ZK的龐大需求,如果ZK證明即時生成可以落地,Web3和傳統產業都有望迎來範式級的變革,但從效率和經濟成本角度來看,目前要讓ZK投入大規模採用還尚且遙遠。
其實,早在2022年,頂級創投機構a16z和Paradigm就公開發表報告,明確表達了對ZK硬體加速的重視,Paradigm甚至斷言:未來ZK礦工的收入可能比肩比特幣或以太坊礦工,基於GPU和FPGA、ASIC的硬體加速方案將具備龐大的市場空間。此後,隨著Scroll和Starknet等主流ZK Rollup的火熱,硬體加速一度成為市場追捧的熱點概念,這種熱度隨著Cysic等項目的臨近上線而變得愈發濃重。
我們有理由認為,基於ZK的巨大需求空間,ZK礦池及實時ZKP生成的SaaS模式可以開闢出嶄新的產業鏈,在這片頗具潛力的新大陸中,有實力支撐且具備先發優勢的ZK硬件廠商完全可能成為下一代的比特大陸,雄踞硬體加速的沃土。
而在硬體加速領域中,Cysic可能是最受關注的勁旅之一,該團隊曾獲得知名ZKP技術競賽平台ZPrize的重要獎項,並在2023年開始作為ZPrize的導師;其路線圖中囊括的ToB端ZK礦池與ToC ZK-Depin硬體更是吸引了Polychain、ABCDE、OKX Ventures和Hashkey等頂級VC的垂青,完成了總計近2,000萬美元的大融資。
隨著7月底Cysic測試網即將上線,以及其ZK礦池的開放在即,各大社區中關於Cysic的討論漸趨熱烈,本文旨在讓更多人了解Cysic的產品原理與業務模式,並對ZK硬體加速原理進行簡單科普。在下文中,我們將對Cysic的相關知識進行簡要概括,幫助更多人降低理解門檻。
從工作流程理解ZK證明系統
ZK證明系統其實是很複雜的,但如果要對其大體構造有個簡單理解,可以從職能和工作流程角度進行分解。對於一個把普通計算ZK化的系統而言,其核心流程概括如下:
首先我們要透過前端與ZK系統交互,向其提交待證明的內容,前端會將這些內容進行格式轉換,以便於被ZK證明系統處理。之後,系統會透過特定的證明系統或框架(如Halo2、Plonk等)產生ZK Proof。這個過程可以細分為以下幾個步驟:
1. 問題設定:首先我們要確定待證明的內容是什麼。例如,證明者Prover聲明自己掌握/知道某樣數據,“我知道方程式F(x)=w的一個解N”,但他又不想讓人看到N的數值。
2.算術化與CSP:證明者提交待證明的內容後,系統會建立專門的數學模型/程序,等價的表達出待證明內容,然後進行格式轉換,以便於被證明系統處理。具體而言,前述聲明「我知道方程式F(x)=w的一個解N」將從原始的數學等式,轉化為邏輯閘電路和多項式的形態。
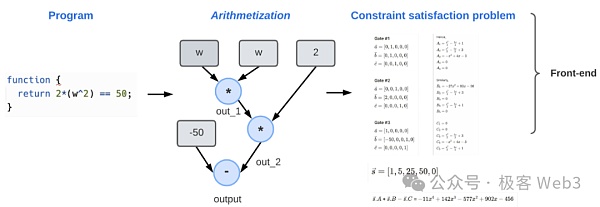
3. 之後,系統將選擇適當的證明系統如Halo、Plonk等,將前面幾步產生的內容編譯為可用的ZKP程式。證明者使用此ZKP程式產生證明,交由驗證者做驗證。
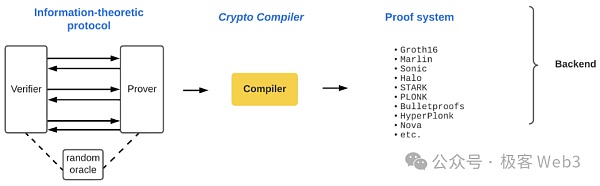
像zkEVM等頻繁在以太坊二層當中被採用的ZK系統,本質是先將智能合約編譯為EVM的底層操作碼,然後對每個操作碼進行格式轉換,轉化為邏輯閘電路/多項式約束的形式,再交由後端的ZK證明系統做進一步處理。
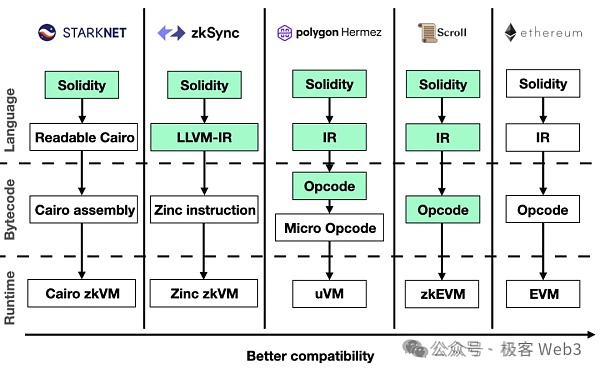
值得一提的是,目前在區塊鏈中被廣泛使用的ZKP技術方案主要是zk-SNARK(零知識簡潔非互動式知識論證),而ZK Rollup大多利用了SNARK的簡潔性而非零知識性。簡潔性意味著ZKP佔用的空間很小,可以把大量的內容壓縮到幾百個位元組,驗證成本非常低。
這樣一來,Prover和Verifier之間的工作量是不對稱的,Prover生成ZKP的成本很高,Verifier的驗證成本卻很低,只要利用好這種不對稱性,在“單一Prover,多個Verifier 「的場景下採用ZK,可以將整體的成本集中在Prover側,極大程度降低Verifier的成本,這種模式對去中心化驗證極其有利,以太坊二層的思路便是如此。
但這種將驗證成本轉嫁到ZK生成端的模式並不是銀彈,對於ZK Rollup專案方而言,生成ZKP付出的高昂成本最終必然會再度轉嫁到UX和手續費上,這並不利於ZK Rollup的長期發展。
縱使ZK在去信任和去中心化驗證的場景下有很大的用武之地,但受限於生成時間上的瓶頸,無論是zkEVM還是zkVM或ZK Rollup和ZK橋,目前都不具備大規模採用的經濟基礎。
對此,以Cysic、Ingonyama、Irreducible等為代表的ZK加速計畫應運而生,分別從不同的方向嘗試降低ZKP的生成成本。下文中,我們將從技術角度簡要介紹ZKP生成的主要開銷與加速方式,以及為何Cysic在ZK加速賽道具備巨大的潛力。
運算開銷:MSM和NTT
很多人都知道,ZKP的Prover產生證明的時間開銷非常的大。在ZK-SNARK協議中經常會出現這樣一種情況:Verifier只需要一秒鐘就可以驗證證明,但是證明的生成可能需要花費Prover半天甚至一天的時間。為了高效的使用ZKP證明計算,有必要將計算格式從經典程式轉換為ZK友善。
目前有兩種方法可以做到這一點:一種是使用一些證明系統框架編寫電路,例如Halo2;另一種是使用領域特定語言(DSL),如Cairo或Circom,將計算轉換為中間表達形式,以便後續提交給證明系統。證明系統會根據所寫的電路或DSL編譯的中間表達形式來產生ZK證明。
程式操作越複雜,產生證明所需的時間就越長。另外,某些操作在本質上對ZK不友好,實現它們需要額外的工作。例如,SHA或Keccak雜湊函數是ZKP不友善的,使用這些函數將導致證明產生時間延長。而即便在經典電腦上執行成本很低的操作,也可能是ZKP不友善的。

而拋開ZK不友善的計算任務不說,雖然ZK證明生成過程可能因選用的證明系統而異,但其瓶頸本質上都是相似的。在ZK證明的生成中,有兩種計算任務最消耗計算資源:MSM(Multi-Scalar Multiplication)和NTT(Number Theoretic Transform)。這兩種計算任務可以佔據證明產生時間的80-95%,取決於ZKP 的承諾方案和具體實現。
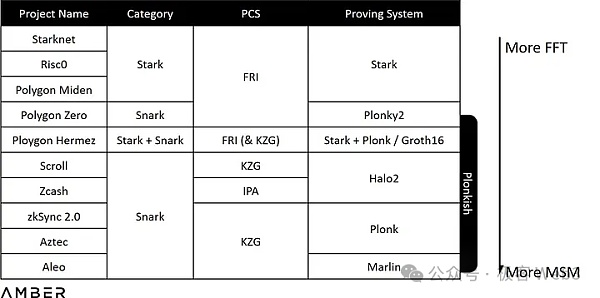
MSM主要處理橢圓曲線上的多標量乘法,而NTT則是在有限域上的FFT(快速傅立葉變換),用於加速處理多項式乘法。使用不同的方案組合將帶來不同的FFT/MSM負載比例。
以Stark為範例,其PCS (Polynomial Commitment Scheme,多項式承諾方案)使用的是FRI,一種基於哈希的承諾,而不是像KZG或IPA所使用的橢圓曲線,因此完全沒有MSM的計算。表中越靠上意味著需要越多的FFT運算,越靠下則需要越多的MSM運算。
最佳化方案
由於MSM運算涉及可預測的記憶體訪問,雖可以大量並行化,但需要消耗大量的記憶體資源。另外,MSM還存在可擴展性挑戰,即使並行化的前提下,也可能很慢,因此,雖然MSM有可能在硬體上加速,但它們需要龐大的記憶體和平行運算資源。
NTT往往涉及隨機內存訪問,這使得它們對硬體不友好,而且在分佈式基礎設施上難以處理,這是因為NTT隨機訪問的特點,其如果在分佈式環境下運行,不可避免地要訪問其他節點的數據,一旦涉及到網絡交互,性能就會大大下降。
因此,儲存資料的存取和資料移動成為一個主要的瓶頸,限制了NTT運算並行化的能力,加速NTT的大部分工作,都集中在管理運算如何與記憶體互動上。
其實,解決MSM和NTT效率瓶頸最簡單的方法,就是要徹底消除這些操作。一些新提出的演算法,例如Hyperplonk,對Plonk進行了修改,消除了NTT操作。這使得Hyperplonk更易於加速,但引入了新的瓶頸;再如計算成本較高的sumcheck協議。還有STARK演算法, 它不需要MSM,但其FRI協定引入了大量雜湊計算。
ZK硬體加速與Cysic的終極目標
儘管軟體和演算法層面的最佳化非常重要且具有價值,但存在明顯的限制。為了充分優化ZKP的生成效率,必須使用硬體加速,這就像ASIC和GPU最終稱霸BTC和ETH挖礦市場。
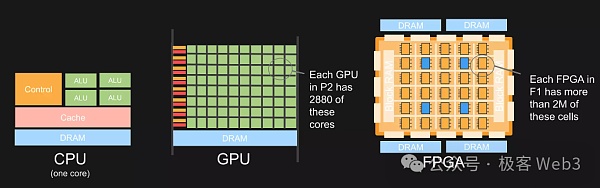
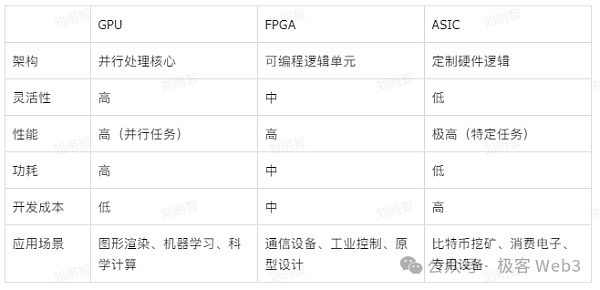
那麼問題是:加速ZKP產生的最佳硬體是什麼?目前有多種硬體可以實現ZK加速,如GPU、FPGA或ASIC,當然他們各有優劣.
我們可以比較一下這幾種硬體:
首先我們透過一個簡單的例子來說明它們在開發層面的差異。例如,現在我們要實作一個簡單的平行乘法:
-
在GPU上,利用CUDA SDK提供的API,我們可以像寫原生程式碼一樣開發,從而獲得平行運算的能力;
-
在FPGA上,我們需要重新學習硬體描述語言,使用這種語言來控制硬體層級的連接,以實現平行演算法;
-
在ASIC上,晶片設計階段硬體層面便直接固定好電晶體的連接排布,之後無法再進行修改。
這幾種方案各有優劣,適用在ZK賽道的不同發展階段。而Cysic致力於成為ZK硬體加速的終極解決方案,逐步策略為:
-
基於GPU開發SDK為ZK應用提供解決方案,並整合全網GPU資源;
-
利用FPGA的靈活性和各項平衡的特點,快速實現客製化的ZK硬體加速。
-
自主研發基於ASIC的ZK Depin硬體
-
而Cysic Network則將以SAAS平台/礦池的身份,整合ZK Depin與GPU的所有算力,為整個ZK產業提供算力與驗證解決方案
以下讓我們透過對多個細分賽道展開解讀,來充分理解ZK加速方案的細分差異與Cysic的發展思維。
ZK礦池與SaaS平台:Cysic Network
其實,無論是Scroll或Polygon zkEVM等知名ZK Rollup,都曾在其路線圖中明確提出了「去中心化Prover」的概念,而這其實就是建構ZK礦池。這種市場化的方式可以讓ZK Rollup專案方減輕包袱,激勵礦工和礦池營運方持續對ZK加速方案進行最佳化。
而在Cysic的路線圖中,已明確提出名為Cysic Network的ZK礦池與SaaS平台計畫。它不但會整合Cysic自有算力,還將透過挖礦激勵的方式吸收第三方算力資源,包括閒散的GPU和一般用戶手上的zk DePIN設備。
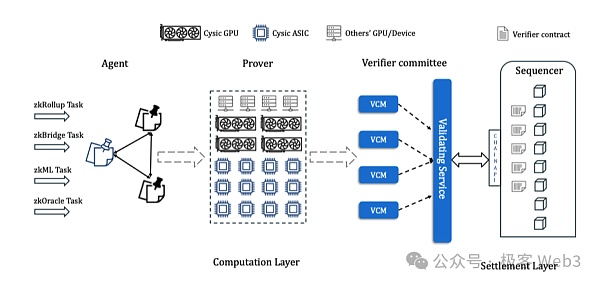
其整個驗證工作流程示意圖如下:
-
zk項目方將證明產生任務提交給代理人(Agent),後者的工作是將證明任務轉送至驗證網路。這些Agent在一開始將由Cysic官方運行,後續將引入資產質押,讓任何人都能成為Agent;
-
Prover接受證明任務,並使用硬體產生ZK證明,證明者需要質押Token來參與證明任務的承包,完成證明任務後將獲得獎勵;
-
驗證者委員會負責檢查Prover產生證明的有效性並進行投票,當達到一定的票數後,證明將被認為有效。驗證者透過質押Token加入委員會,參與投票並獲得獎勵,這個過程可以結合EigenLayer的AVS概念,復用現有的Restaking設施。
其詳細交互過程如下:
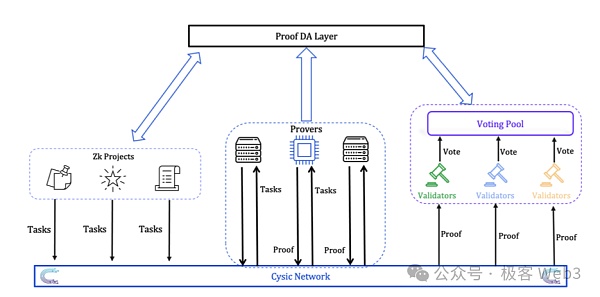
其實上面的流程中有個點,無論是資產質押還是激勵分發,以及計算任務的提交等動作都需要依賴某個專屬平台,這就需要有區塊鏈作為專用設施。
為此Cysic Network搭建了一條專屬公鏈,採用了一種獨特的共識演算法,稱為Proof of Compute (PoC),其基本原理是基於VRF函數和Prover的歷史表現,例如設備的可用性、提交證明次數、Proof正確率等等,來選擇出塊人負責出塊(註:它這裡的區塊應該是用來記錄各台設備的資訊和分發Token激勵)。
當然,在ZK礦池和SaaS平台之外,Cysic基於不同硬體的ZK加速方案上都進行了大量佈局。接下來讓我們分別了解在GPU、FPGA和ASIC三條路線上的成果。
GPU、FPGA和ASIC
ZK硬體加速的核心在於盡可能將一些關鍵運算並行化。而從硬體的功能特性來看,CPU為了實現最大的靈活和通用,晶片中很大一部分面積都用來提供控制功能和各級緩存,這導致其並行運算能力較弱。
在GPU當中,用作運算的晶片面積比例大大提高,這使其能夠支援大規模的並行處理。現在GPU已經非常普及,例如Nvidia Cuda等函式庫可以幫助開發人員利用GPU的並行性,而無需了解底層硬件,透過CUDA SDK可以封裝CUDA ZK函式庫加速MSM和NTT運算。
而FPGA則由大量小型處理單元組成的陣列,要對FPGA進行編程,需使用專門的硬體描述語言,再編譯為電晶體電路組合。所以FPGA其實是直接用電晶體電路實作特定演算法,而不需要經過指令系統的編譯。這種客製化性和靈活性遠勝於GPU。
目前FPGA價格大約僅是GPU的三分之一,且能源效率可以比GPU高出十倍以上。這種顯著的能源效率優勢部分原因在於GPU需要連接到主機設備,而主機設備通常消耗大量電力。可以說,FPGA可以在不增加能耗的情況下,增加更多的運算模組來應付MSM和NTT的需求。這使得FPGA特別適合計算密集、需要高資料吞吐量和低迴應時間的ZK證明場景。
然而,FPGA最大的問題是鮮少有開發人員具備程式設計經驗,對於ZK專案方而言,組織一個既擁有密碼學專業知識、同時擁有FPGA工程專業知識的團隊極為困難。
而ASIC則相當於完全用硬體來實現某個程序,一旦設計完畢,硬體就無法更改,相應地,ASIC能夠執行的程序自然也無法更改,只能用作特定任務。上述的FPGA在MSM和NTT方面的硬體加速優點,ASIC同樣也具備。而由於是專用電路設計,ASIC在所有方案裡是效能最高、能耗最小的。
對於目前主流的ZK Circuit,Cysic希望證明時間能達到1 – 5 秒的速度,想要達到這個目標,只有ASIC能夠實現。
雖然這些優點聽起來非常吸引人,但ZK技術正在快速發展,而ASIC的設計和生產週期通常需要1-2年,並且成本高達1000-2000萬美元。因此,必須要等到ZK技術夠穩定,才能投入大規模的生產,以避免生產出的晶片很快就過時。
對此,在GPU和FPGA、ASIC這三個領域,Cysic都做了充分佈局;
在GPU加速方案層面,隨著各種新型ZK證明系統的誕生,Cysic基於自研CUDA加速SDK對它們進行了適配,並透過聚攏社區資源的方式,在Cysic的GPU算力網絡中連結了數十萬張頂級算力顯示卡,同時Cysic CUDA SDK比最新的開源框架提速了50%-80%甚至以上。
在FPGA上,Cysic透過自研方案,完成了全球最快的MSM、NTT、Poseidon Merkle tree等模組的實現,涵蓋了ZK計算最主要的部分,而且該方案經過了多個頂級ZK項目的原型驗證。
Cysic自研的SolarMSM可以在0.195秒內完成2^30規模的MSM計算,而SolarNTT能在0.218秒內完成2^30規模的NTT計算,是目前所有公開的FPGA硬體加速結果中性能最高的。


而在ASIC領域,雖然距離ZK ASIC的大規模應用還有一段距離,但Cysic已經提前佈局了這條賽道,並推出了自主研發的ZK DePIN晶片和設備。
為了吸引C端用戶,並滿足不同ZK專案方對效能和成本的要求,Cysic將推出兩款ZK硬體產品:ZK Air和ZK Pro。

ZK Air的大小與行動電源、筆記型電腦電源相近,一般用戶可以直接透過Type-C介面連接到筆電、iPad甚至手機上,為特定ZK專案提供算力支援並獲得獎勵。目前ZK Air算力仍超越消費級顯示卡,可以加速小規模的ZK證明生成任務。
ZK Pro則類似於傳統礦機,算力達到了多塊頂級消費級顯示卡互聯GPU伺服器的效果,能夠大幅加速ZK證明的生成,適用於大型ZK項目,如ZK-Rollup和ZKML(Zero knowledge machine learning )。
透過這兩款設備,Cysic最終將建立一個穩定可靠的ZK-DePIN網路。目前這兩款設備還在研發中,預計2025年上市。
此外,透過Cysic Network,C端用戶能夠以非常低的門檻加入到zk硬體加速市場,加上ZK專案方對算力的大量需求,這可能使市場再次掀起一波如同比特幣挖礦一樣的熱潮,ZK計算領域的市場規模可能將再次迎來爆發式成長。
reference
https://medium.com/amber-group/need-for-speed-zero-knowledge-1e29d4a82fcd
https://figmentcapital.medium.com/accelerating-zero-knowledge-proofs-cfc806de611b