

撰文:Geng Kai、Eric,DFG
引言
自2023 年以來,AI 和DePIN 都是Web3 中的熱門趨勢,其中AI 的市值為300 億美元,而DePIN 的市值為230 億美元。這兩個類別非常龐大,每個類別都涵蓋了各種不同的協議,這些協議服務於不同的領域和需求,應該單獨涵蓋。然而,本文旨在討論兩者之間的交集,並研究該領域協議的發展。
在AI 技術堆疊中,DePIN 網路透過運算資源為AI 提供實用性。大型科技公司的發展導致GPU 短缺,這導致其他正在建立自己的AI 模型的開發人員缺乏足夠的GPU 進行運算。這通常會導致開發人員選擇中心化雲端供應商,但由於必須簽署不靈活的長期高效能硬體合同,導致效率低下。
DePIN 本質上提供了一種更靈活且更具成本效益的替代方案,它使用代幣獎勵來激勵符合網路目標的資源貢獻。人工智慧中的DePIN 將GPU 資源從個人所有者眾包到資料中心,為需要存取硬體的使用者形成統一的供應。這些DePIN 網路不僅為需要運算能力的開發人員提供可自訂性和按需訪問,還為可能難以透過閒置獲利的GPU 所有者提供額外收入。
市場上有如此多的AI DePIN 網絡,可能很難識別它們之間的差異並找到所需的正確網絡。在下一部分中,我們將探討每種協議的作用以及它們試圖實現的目標,以及它們已經實現的一些具體亮點。
AI DePIN網路概述
這裡提到的每個項目都有一個類似的目的—GPU 運算市場網路。本文這一部分的目的是研究每個項目的亮點、它們的市場重點以及它們所取得的成就。透過先了解它們的關鍵基礎設施和產品,我們可以深入了解它們之間的差異,這將在下一節中介紹。
Render是提供GPU 運算能力的P2P 網路的先驅,之前專注於為內容創作渲染圖形,後來透過整合Stable Diffusion等工具集,將其範圍擴展到包括從神經反射場(NeRF) 到生成AI 的AI計算任務。
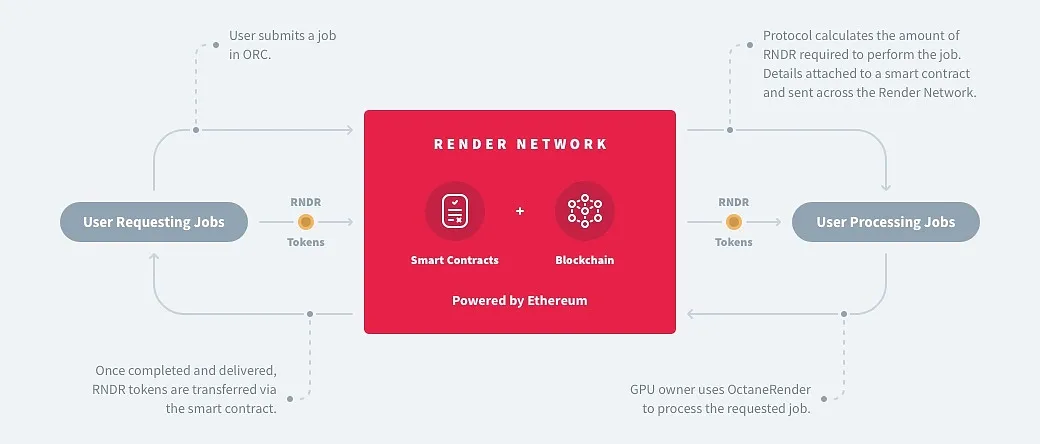
有趣之處:
-
由擁有奧斯卡獲獎技術的雲端圖形公司OTOY 創立
-
GPU 網路已被派拉蒙影業、PUBG、星際爭霸戰等娛樂產業的大公司所使用
-
與Stability AI 和Endeavor 合作,利用Render 的GPU 將他們的AI 模型與3D 內容渲染工作流程整合
-
核准多個運算客戶端,整合更多DePIN 網路的GPU
Akash將自己稱為“託管版Airbnb”,將自己定位為支援儲存、GPU 和CPU 運算的傳統平台(如AWS)的「超級雲端」替代品。利用Akash 容器平台和Kubernetes 管理的運算節點等開發人員友善工具,它能夠跨環境無縫部署軟體,從而能夠運行任何雲端原生應用程式。
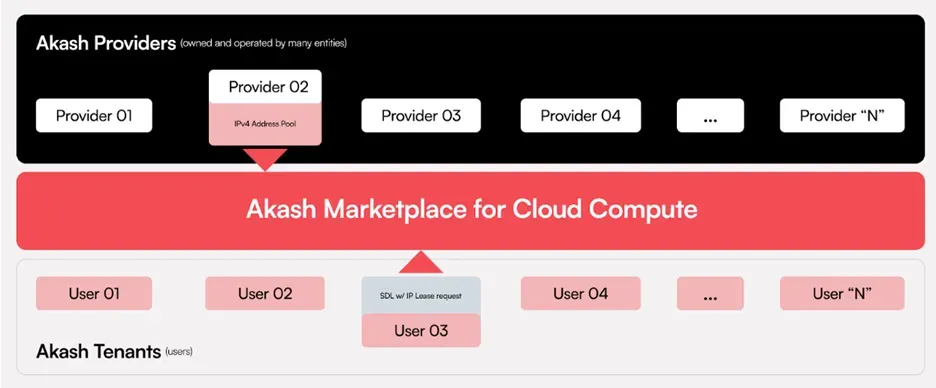
有趣之處:
-
針對從通用運算到網站寄存的廣泛運算任務
-
AkashML 允許其GPU 網路在Hugging Face 上運行超過15,000 個模型,同時與Hugging Face 集成
-
Akash 上託管著一些值得注意的應用程序,例如Mistral AI 的LLM 模型聊天機器人、Stability AI 的SDXL文字轉圖像模型,以及Thumper AI 的新基礎模型AT-1
-
建構元宇宙、人工智慧部署和聯邦學習的平台正在利用Supercloud
io.net提供對分散式GPU 雲端叢集的訪問,這些叢集專門用於AI 和ML 用例。它聚合了來自資料中心、加密礦工和其他去中心化網路等領域的GPU。該公司之前是一家量化交易公司,在高性能GPU 價格大幅上漲後,該公司轉向了目前的業務。
有趣之處:
-
其IO-SDK 與PyTorch 和Tensorflow 等框架相容,其多層架構可根據運算需求自動動態擴展
-
支援建立3 種不同類型的集群,可在2 分鐘內啟動
-
強而有力的合作努力,以整合其他DePIN 網路的GPU,包括Render、Filecoin、Aethir 和Exabits
Gensyn提供專注於機器學習和深度學習運算的GPU 運算能力。它聲稱與現有方法相比,透過結合使用諸如用於驗證工作的學習證明、用於重新運行驗證工作的基於圖形的精確定位協議以及涉及計算提供商的質押和削減的Truebit 式激勵遊戲等概念,實現了更有效率的驗證機制。
有趣之處:
-
預計V100 等效GPU 的每小時成本約為0.40 美元/小時,從而大幅節省成本
-
透過證明堆疊,可以對預先訓練的基礎模型進行微調,以完成更具體的任務
-
這些基礎模型將是去中心化的、全球擁有的,除了硬體運算網路之外還提供額外的功能
Aethir專門搭載企業GPU,專注於運算密集領域,主要是人工智慧、機器學習(ML)、雲端遊戲等。其網路中的容器充當執行基於雲端的應用程式的虛擬端點,將工作負載從本地設備轉移到容器,以實現低延遲體驗。為了確保為用戶提供優質服務,他們根據需求和位置將GPU 移近資料來源,從而調整資源。
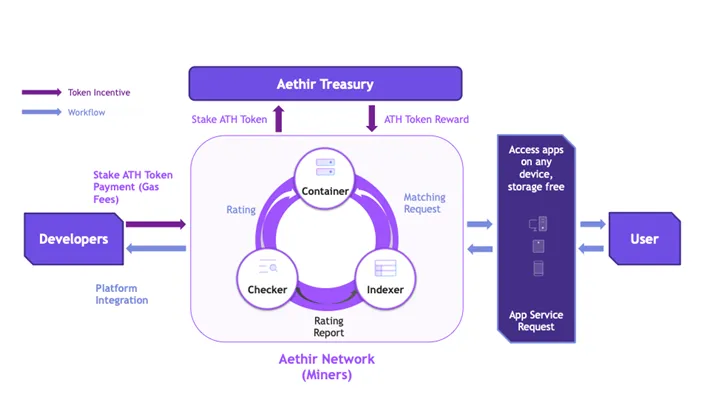
有趣之處:
-
除了人工智慧和雲端遊戲,Aethir 還擴展到雲端手機服務,並與APhone 合作推出去中心化的雲端智慧型手機
-
與NVIDIA、Super Micro、HPE、富士康和Well Link 等大型Web2 公司建立了廣泛的合作夥伴關係
-
Web3 中的多個合作夥伴,例如CARV、Magic Eden、Sequence、Impossible Finance 等
Phala Network扮演Web3 AI 解決方案的執行層。其區塊鏈是一種無需信任的雲端運算解決方案,透過使用其可信任執行環境(TEE) 設計來處理隱私問題。其執行層不是用作AI 模型的計算層,而是使AI 代理能夠由鏈上的智能合約控制。
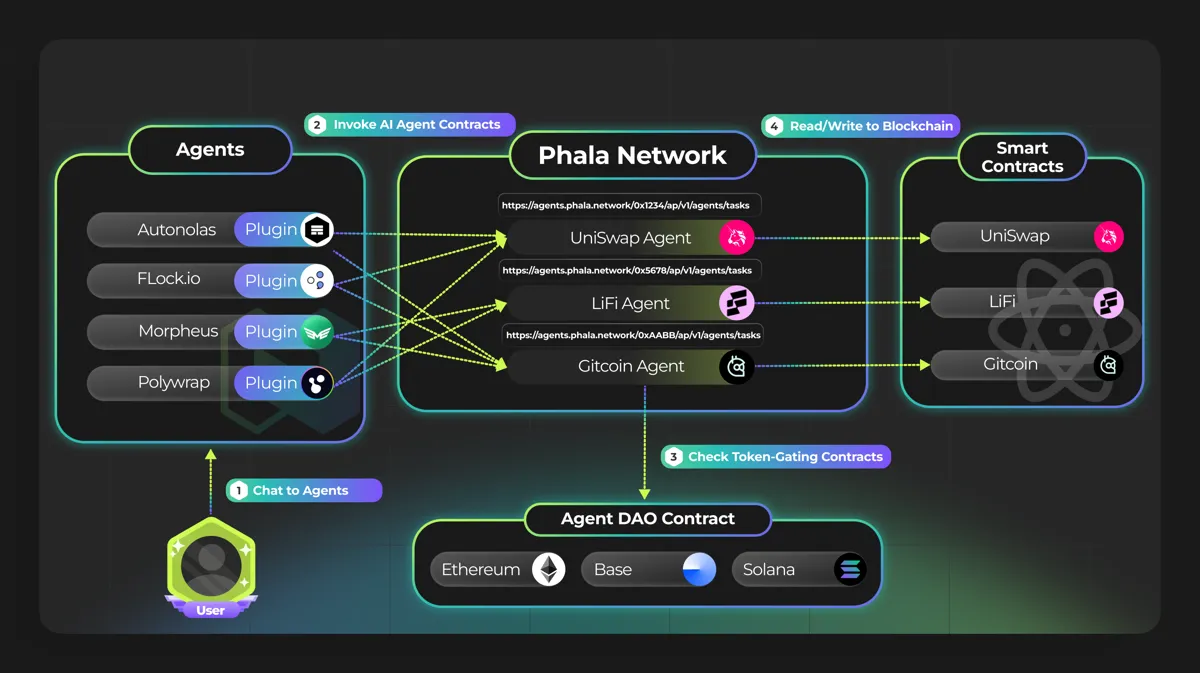
有趣之處:
-
充當可驗證計算的協處理器協議,同時也使AI 代理能夠鏈上資源
-
其人工智慧代理合約可透過Redpill 獲得OpenAI、Llama、Claude 和Hugging Face 等頂級大型語言模型
-
未來將包括zk-proofs、多方計算(MPC)、全同態加密(FHE) 等多重證明系統
-
未來支援H100等其他TEE GPU ,提升運算能力
項目比較
Render
Akash
io.net
Gensyn
Aethir
Phala
硬體
GPU & CPU
GPU & CPU
GPU & CPU
GPU
GPU
CPU
業務重點
圖形渲染和AI
雲端運算、渲染和AI
AI
AI
人工智慧、雲端遊戲和電信
鏈上AI 執行
AI任務類型
推理
Both
Both
訓練
訓練
執行
工作定價
基於表現的定價
反向拍賣
市場定價
市場定價
招標系統
權益計算
區塊鏈
Solana
Cosmos
Solana
Gensyn
Arbitrum
Polkadot
資料隱私
加密&雜湊
mTLS 驗證
資料加密
安全映射
加密
TEE
工作費用
每項工作0.5-5%
20% USDC,
4% AKT
2% USDC,0.25%
準備金費用
費用低廉
每一個session 20%
與質押金金額成比例
安全
渲染證明
權益證明
計算證明
權益證明
渲染能力證明
繼承自中繼鏈
完成證明
–
–
時間鎖證明
學習證明
渲染工作證明
TEE 證明
品質保證
爭議
–
–
核實者和檢舉人
檢查器節點
遠端證明
GPU 叢集
否
是
是
是
是
否
重要性
叢集和並行運算的可用性
分散式運算框架實現了GPU 集群,在不影響模型準確性的情況下提供更有效率的訓練,同時增強了可擴展性。訓練更複雜的AI 模型需要強大的運算能力,這通常必須依靠分散式運算來滿足其需求。從更直觀的角度來看,OpenAI 的GPT-4 模型擁有超過1.8 兆個參數,在3-4 個月內使用128 個叢集中的約25,000 個Nvidia A100 GPU 進行訓練。
先前,Render 和Akash 僅提供單一用途的GPU,這可能會限制其對GPU 的市場需求。不過,大多數重點項目現在都已整合了叢集以實現平行計算。 io.net 與Render、Filecoin 和Aethir 等其他專案合作,將更多GPU 納入其網絡,並已成功在24 年第一季部署了超過3,800 個叢集。儘管Render 不支援集群,但它的工作原理與集群類似,將單個幀分解為多個不同的節點,以同時處理不同範圍的幀。 Phala 目前僅支援CPU,但允許將CPU 工作器叢集化。
將叢集框架納入AI 工作流程網路非常重要,但滿足AI 開發人員需求所需的叢集GPU 數量和類型是一個單獨的問題,我們將在後面的部分中討論。
資料隱私
開發AI 模型需要使用大量資料集,這些資料集可能來自各種來源,形式各異。個人醫療記錄、使用者財務資料等敏感資料集可能面臨暴露給模型提供者的風險。三星因擔心敏感程式碼上傳到平台會侵犯隱私而內部禁止使用ChatGPT,微軟的38TB 私人資料外洩事故進一步凸顯了在使用AI 時採取足夠安全措施的重要性。因此,擁有各種資料隱私方法對於將資料控制權交還給資料提供者至關重要。
所涵蓋的大多數項目都使用某種形式的資料加密來保護資料隱私。資料加密可確保網路中從資料提供者到模型提供者(資料接收者)的資料傳輸受到保護。 Render 在將渲染結果發布回網路時使用加密和雜湊處理,而io.net 和Gensyn 則採用某種形式的資料加密。 Akash 使用mTLS 身份驗證,僅允許租戶選擇的提供者接收資料。
然而,io.net 最近與Mind Network 合作推出了完全同態加密(FHE),允許在無需先解密的情況下處理加密資料。透過讓資料能夠安全地傳輸用於培訓目的而無需洩露身分和資料內容,這項創新可以比現有的加密技術更好地確保資料隱私。
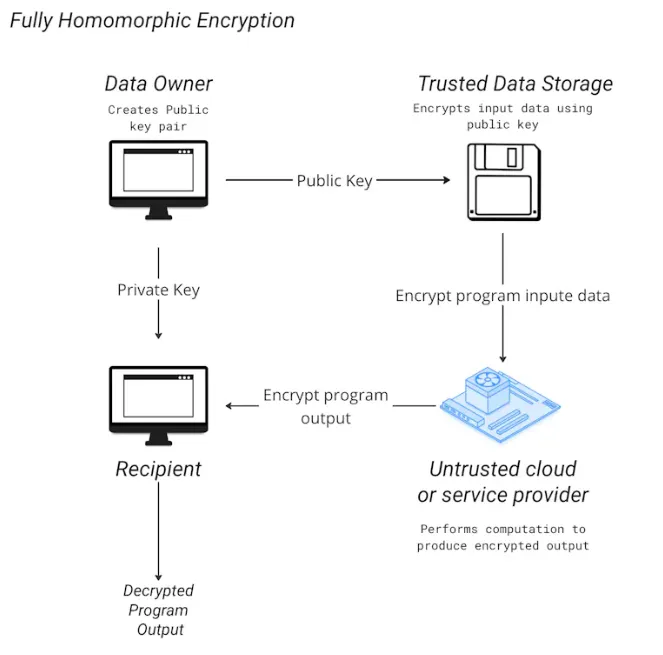
Phala Network 引進了TEE,即連接裝置主處理器中的安全區域。透過這種隔離機制,它可以防止外部進程存取或修改數據,無論其權限級別如何,即使是對機器具有物理存取權限的個人。除了TEE 之外,它還在其zkDCAP 驗證器和jtee命令列介面中結合了zk-proofs 的使用,以便與RiscZero zkVM 整合的程式。
計算完成證明和品質檢查
這些項目提供的GPU 可為一系列服務提供運算能力。由於這些服務範圍廣泛,從渲染圖形到AI 計算,因此此類任務的最終品質可能不一定總是符合使用者的標準。可以使用完成證明的形式來表示用戶租用的特定GPU 確實用於運行所需的服務,並且品質檢查對請求完成此類工作的用戶有益。
計算完成後,Gensyn 和Aethir 都會產生證明以表明工作已完成,而io.net 的證明則表明租用的GPU 的性能已充分利用且沒有出現問題。 Gensyn 和Aethir 都會對已完成的計算進行品質檢查。對於Gensyn,它使用驗證者重新運行生成的證明的部分內容以與證明進行核對,而舉報人則充當對驗證者的另一層檢查。同時,Aethir 使用檢查節點來確定服務質量,對低於標準的服務進行處罰。 Render 建議使用爭議解決流程,如果審查委員會發現節點有問題,則削減該節點。 Phala 完成後會產生TEE 證明,確保AI 代理在鏈上執行所需的操作。
硬體統計數據
Render
Akash
io.net
Gensyn
Aethir
Phala
GPU數量
5600
384
38177
–
40000+
–
CPU數量
114
14672
5433
–
–
30000+
H100/A100數量
–
157
2330
–
2000+
–
H100費用/小時
–
$1.46
$1.19
–
–
–
A100費用/小時
–
$1.37
$1.50
$0.55 (預計)
$0.33 (預計)
–
高性能GPU 的需求
由於AI 模型訓練需要最佳表現的GPU,因此他們傾向於使用Nvidia 的A100 和H100 等GPU,儘管後者在市場上的價格很高,但它們提供最佳品質。看看A100 如何不僅能夠訓練所有工作負載,還能以更快的速度完成訓練,這只能說明市場對這種硬體的重視程度。由於H100 的推理性能比A100 快4 倍,因此它現在已成為首選GPU,尤其是對於正在訓練自己的LLM 的大型公司而言。
對於去中心化的GPU 市場供應商來說,要想與Web2 同行競爭,它不僅要提供更低的價格,還要滿足市場的實際需求。 2023年,Nvidia 向中心化的大型科技公司交付了超過50 萬台H100,這使得獲取盡可能多的同等硬體以與大型雲端供應商競爭變得成本高昂且困難重重。因此,考慮這些項目可以以低成本帶入其網路的硬體數量對於將這些服務擴展到更大的客戶群非常重要。
雖然每個項目都在AI 和ML 運算方面有業務,但它們在提供運算的能力方面有所不同。 Akash 總共只有150 多個H100 和A100 單元,而io.net 和Aethir 則分別獲得了2000 多個單元。通常,從頭開始預訓練LLM 或生成模型需要叢集中至少248 到2000 多個GPU,因此後兩個專案更適合大型模型計算。
根據此類開發人員所需的叢集大小,目前市場上這些去中心化GPU 服務的成本已經比中心化GPU 服務低得多。 Gensyn 和Aethir 都宣稱能夠以每小時不到1 美元的價格租用相當於A100 的硬件,但這仍需要隨著時間的推移得到證明。
網路連接的GPU 叢集擁有大量GPU,每小時成本較低,但與NVLink 連接的GPU 相比,它們的一個問題是記憶體受限。 NVLink支援多個GPU 之間的直接通信,無需在CPU 和GPU 之間傳輸數據,即可實現高頻寬和低延遲。與網路連接的GPU 相比,NVLink 連接的GPU 最適合具有許多參數和大型資料集的LLMS,因為它們需要高效能和密集運算。
儘管如此,對於那些具有動態工作負載需求或需要靈活性和跨多個節點分配工作負載能力的用戶來說,去中心化GPU 網路仍可為分散式運算任務提供強大的運算能力和可擴展性。透過提供比中心化雲端或資料提供者更具成本效益的替代方案,這些網路為建構更多AI 和ML 用例開啟了寡占局面,而不像中心化AI 模型那樣。
提供消費級GPU/CPU
儘管GPU 是渲染和運算所需的主要處理單元,但CPU 在訓練AI 模型方面也發揮著重要作用。 CPU 可用於訓練的多個部分,包括資料預處理一直到記憶體資源管理,這對開發人員開發模型非常有用。消費級GPU 還可用於較不密集的任務,例如對已經預先訓練好的模型進行微調或以更實惠的成本在較小的資料集上訓練較小規模的模型。
儘管Gensyn 和Aethir 等專案主要專注於企業級GPU,但考慮到超過85% 的消費者GPU 資源處於閒置狀態,Render、Akash 和io.net 等其他專案也可以服務這部分市場。提供這些選項可以讓他們開發自己的市場利基,讓他們專注於大規模密集型運算、更通用的小規模渲染或兩者之間的混合。
結論
AI DePIN 領域仍然相對較新,面臨著自身的挑戰。他們的解決方案因其可行性而受到批評,並遭遇挫折。例如,io.net 被指控偽造其網路上的GPU 號碼,後來透過引入工作量證明流程來驗證設備並防止女巫攻擊,解決了這個問題。
儘管如此,這些去中心化GPU 網路中執行的任務和硬體數量仍顯著增加。這些網路上執行的任務量不斷增加,凸顯了對Web2 雲端供應商硬體資源替代品的需求不斷增長。同時,這些網路中硬體供應商的激增凸顯了先前未充分利用的供應。這一趨勢進一步證明了AI DePIN 網路的產品市場契合度,因為它們有效地解決了需求和供應方面的挑戰。
展望未來,人工智慧的發展軌跡指向一個蓬勃發展的數萬億美元的市場,我們認為這些分散的GPU 網路將在為開發人員提供經濟高效的運算替代方案方面發揮關鍵作用。透過利用其網路不斷彌合需求和供應之間的差距,這些網路將為人工智慧和運算基礎設施的未來格局做出重大貢獻。
