完整的區塊鏈系統內部一定會包含一個「存儲模塊」,整體而言,區塊鏈系統確實可以起到持久化數據的作用。但是如果直接將區塊鏈系統看作是一個數據庫,也是有待商榷的。我們來分析一下傳統數據庫系統的運行機制以及區塊鏈系統內部存儲模塊的功能職責。
【背景】
隨著區塊鏈技術的發展和應用場景的逐步豐富,越來越多的人開始接觸區塊鏈。但在過程中,很多人提過這樣的問題:“底層用區塊鏈系統和用數據庫有什麼區別呢?”、“區塊鏈系統是不是就是一個OLTP數據庫系統?”…
直觀的角度來看,完整的區塊鏈系統內部一定會包含一個「存儲模塊」,整體而言,區塊鏈系統確實可以起到持久化數據的作用。
但是如果從這個角度出發,直接將區塊鏈系統看作是一個數據庫,這樣的觀點也是有待商榷的。在作出最終比較之前,我們先來分析一下傳統數據庫系統的運行機制以及區塊鏈系統內部存儲模塊的功能職責。 【傳統OLTP數據庫VS區塊鏈存儲】
▲ 傳統OLTP數據庫存什麼?
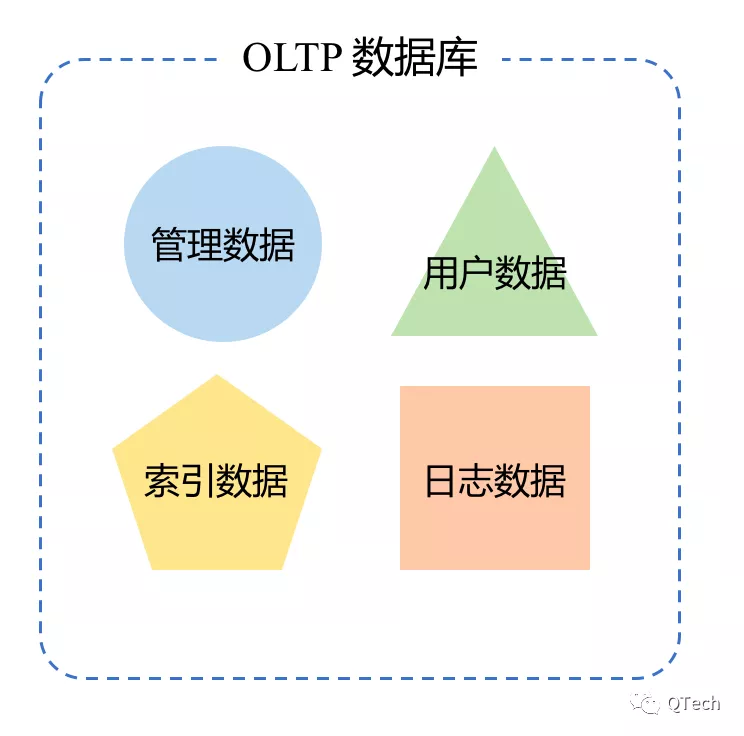
現階段的數據庫系統、存儲引擎的設計一般是面向某一通用場景的,比如sql型數據庫、NoSQL型數據庫(kv數據庫、文檔數據庫等),而不是面向具體業務場景的,那一般的OLTP數據庫內部的數據分為四大類:
數據庫內部的管理性質的元數據。這部分數據基本上對用戶是透明的,負責數據庫內部的管理與控制邏輯;
用戶自定義數據。這部分數據是用戶通過API向數據庫寫入的數,數據庫系統一般不關心這部分數據的具體內容,而是側重於如何正確、完整的將這些數據保存到持久化設備;
索引數據。索引數據一般是數據庫設計中不可或缺的一個組成部分。為了保證數據庫“讀數據”功能的響應時間在用戶可接受範圍內,幾乎所有數據庫系統都需要或多或少的引入索引;
日誌數據。日誌數據是一種數據庫內部數據,其內容一般是記錄數據變更行為,一般用於數據庫宕機重啟後的數據恢復。在不同的數據庫中,日誌數據的內容差距也非常大,比如:有的數據庫使用日誌來記錄存儲層的數據變更(磁盤上位置X開始,連續N個字節從Value1變成了Value2),有的數據庫使用日誌來記錄用戶的寫入命令請求(比如插入操作,內容為key=1,value=”ABC”)等等。
圖片
▲ 區塊鏈存儲模塊有何不同?
當我們站在區塊鏈系統內部“數據存儲”功能的角度看待“區塊鏈系統”時,我們會發現,區塊鏈系統具有確定性的系統架構、確定性的內部業務邏輯,以及一些通用的數據組織格式(比如:區塊是一種append-only形式的數據、只有虛擬機執行指令的過程中會修改狀態數據等)。區塊鏈系統中的數據存儲只需要滿足這一套運轉邏輯過程中的持久化需求即可,也就是說,區塊鏈系統為其存儲模塊劃定了比通用數據庫更小的模塊功能邊界。
▲區塊鏈存儲存什麼? ——世界狀態
從使用者角度來看,一個最常規的區塊鏈服務是由一個區塊鍊網絡提供的。區塊鍊網絡由多個節點構成,用戶可以向區塊鏈服務發送交易,區塊鍊網絡中的所有參與共識的節點會針對交易的內容、執行過程、執行結果達成一致的決議,並將執行結果返回給發起交易的用戶。
上述過程是一個最常規的區塊鏈服務使用流程。但是,如果從區塊鍊網絡中的節點的角度出發,節點感知的過程或者變化有哪些呢?
我們略去網絡交互、共識、執行等等的細節說明,直接討論我們關注的重點——“世界狀態”:
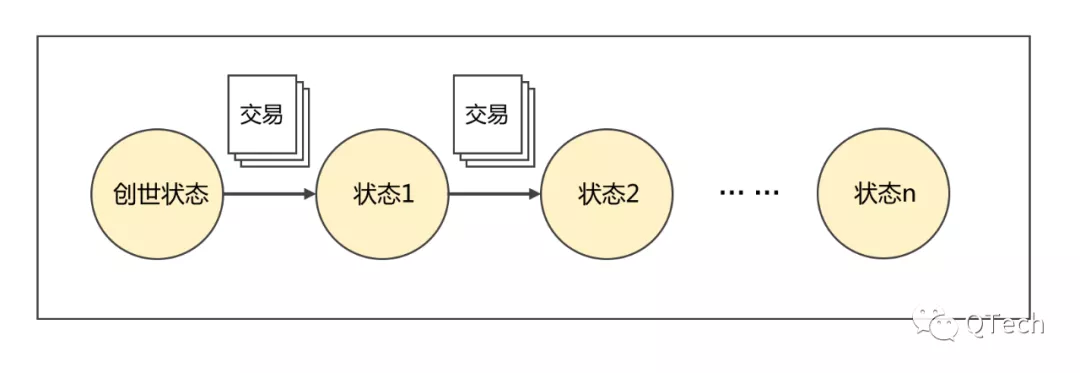
如果我們將區塊鏈可以看為一個分佈式的狀態機:所有節點從同一個創世狀態開始,依次執行相同順序的交易,驅動各個節點的狀態按照相同操作序列不斷變化,實現所有節點在同一交易序列執行完成後,狀態完全一致。而這個狀態,就稱為“世界狀態”。
 圖片
圖片
在區塊鍊網路中,所有誠實節點本地維護的“世界狀態”是一致的,這個“世界狀態”就是區塊鏈存儲模塊要重點關注的內容。
解釋了“世界狀態” 的定義,我們還是要關注“世界狀態” 到底包括什麼內容:首先,一個區塊鏈系統中的數據狀態的更迭,一定是由“用戶交易” 驅動的,那麼我們只需要保證’世界狀態’ 能夠涵蓋交易的“請求內容、執行過程和執行結果” 三部分內容,就可以滿足上述“分佈式狀態機” 中的一致性要求。
接下來,我們將從三個角度分別分析“世界狀態”中要存儲的具體內容。
區塊鏈系統通用的存儲內容——塊鏈結構
區塊鏈系統中,區塊通過保存前序區塊的標識(一般都是用區塊哈希)來形成邏輯上的一條鏈。這樣做的目的和意義本文不再贅述,這裡重點關注的是這個“區塊”的數據組織和存儲形式。
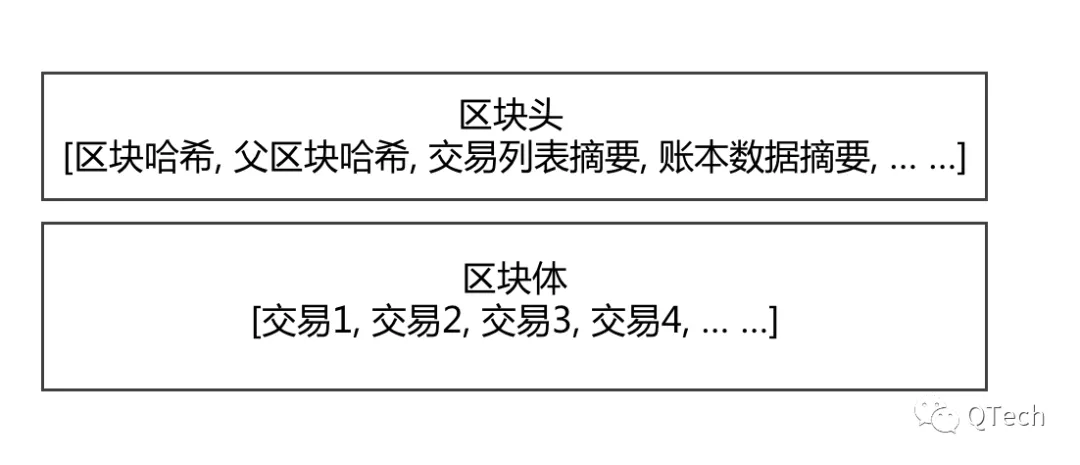
區塊裡面會存儲哪些內容呢?一般的區塊鏈系統中,區塊會被分為區塊頭和區塊體兩個部分。
“區塊體” 部分相對簡單,這個部分負責將交易內容按照一個確定的順序存儲下來;存儲交易內容是很好理解的,但“一個確定的順序”是指什麼呢?回顧上文,“世界狀態”是由交易驅動的,不同的交易執行順序可能會導致數據變更操作的順序不同,進而很可能導致世界狀態的不同。因此“區塊體”的內容,即體現了完整的交易內容,還同時體現了確定的交易順序。
“區塊頭”部分會包含很多的元素,區塊頭中一般會包含一個最重要的區塊哈希字段,這個區塊哈希一般會用於表示當前系統的世界狀態。這就要求區塊哈希的計算來源至少包含:前一區塊的區塊哈希(代表了前序的世界狀體)、當前區塊對世界狀態造成的變更影響(當前區塊包含的所有交易的內容、執行結果和執行過程中對賬本數據的修改)。但是,區塊哈希的具體計算方式可以由執行層來決定,不同系統間計算方式不盡相同[1][2]。
 圖片注:目前也存在一些新型的區塊鏈系統採用了DAG模型[3]組織交易,甚至形成區塊結構,這種情況本文暫時不做分析。
圖片注:目前也存在一些新型的區塊鏈系統採用了DAG模型[3]組織交易,甚至形成區塊結構,這種情況本文暫時不做分析。
賬本數據——UTXO模型賬本VS賬戶模型賬本
區塊數據內部包含了交易內容,但是交易的內容一般只定義了對區塊鏈上數據的修改請求,“執行過程” 和“執行結果” 這兩部分數據可能並不包含於交易內容中。本節將首先討論交易“執行過程” 對“世界狀態” 的影響。為此,我們引入了“賬本數據” 的概念。
目前比較通用的賬本數據組織形式包括:UTXO模型和賬戶模型。
UTXO模型相對比較簡單,系統中僅支持一種運行模式:“UTXO” 在不同的賬戶間流通。在這種運作模式下,一筆交易代表了一次流通行為,具體的流通過程為:輸入的UTXO被銷毀,輸出的UTXO被創建,輸入總額需要大於或等於輸出總額[4]。
在UTXO模型下的賬本數據定義較為直觀:當前鏈上全量的未消費的UTXO(包括UTXO上的綁定的腳本)。因為在這種模式下,如果交易執行成功,則輸出有效,如果交易執行失敗,則輸出無效。而執行過程中的鎖定、解鎖等腳本的驗證過程不會產生額外的賬本數據修改。因此交易執行過程不涉及賬本數據的更改。
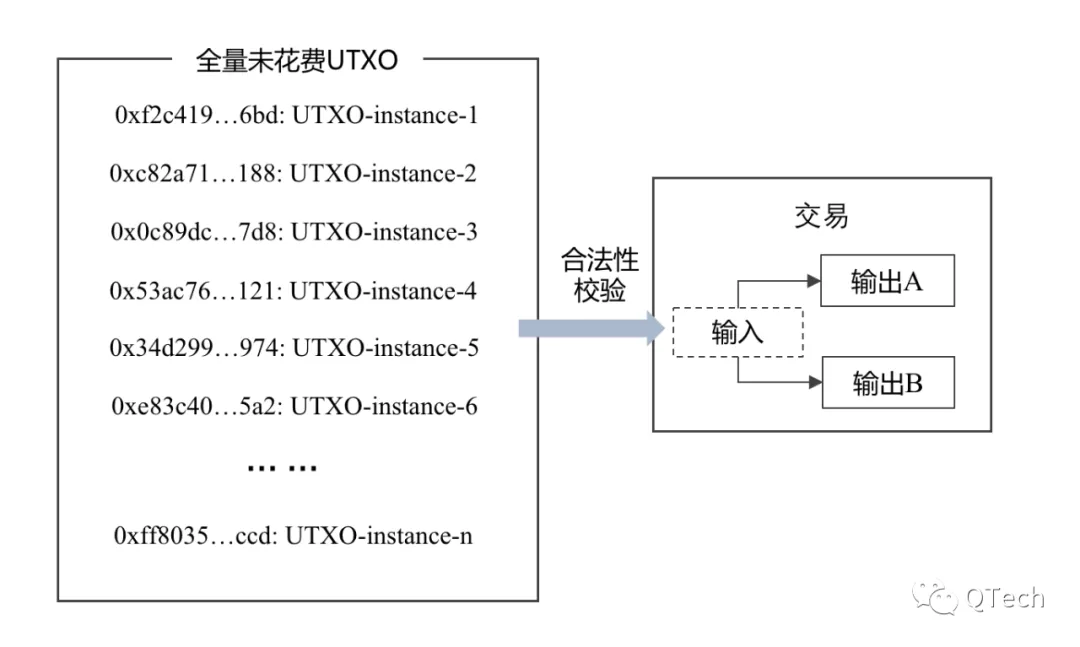 圖片
圖片
但是賬戶模型的賬本組織方式會略微複雜一些。一般賬戶模型的賬本都是可以支持“智能合約” 的,賬戶模型下的區塊鏈系統會建立一個“賬戶空間” 。
“賬戶空間” 是由很多個賬戶組成的,其中的賬戶可能分為多種類型。以以太坊為例,系統中以一個通用的數據結構定義了普通賬戶、合約賬戶兩種類型。普通賬戶的行為包括:發起交易、互相轉賬、創建賬戶等等;而合約賬戶則對應了一份部署在鏈上的智能合約,相應的,合約賬戶會管理所有在這份智能合約中定義的、需要存儲到區塊鏈賬本中的key-value數據對,我們稱之為“狀態數據” 。
在交易執行的過程中,可能涉及到“賬戶數據” 和“狀態數據” 的變更,這些改變可能既不會體現在合約內容本身中,也不會體現在交易執行結果中。因此,為了保證“世界狀態” 的完整性,經過交易執行修改後的整個“賬戶空間” 的數據狀態,需要被納入“世界狀態”的範疇。
那麼作為世界狀態的一部分,系統會規定一種特定的方式(以太坊的MPT樹、Fabric的bucketTree等等)計算出一個能反應賬戶空間整體狀態的、易於比較的結果值,這個結果值會參與到上一節提到的“區塊哈希”的計算中。 (某些計算過程中的數據可能也會被持久化,比如MPT會將計算樹根過程中的路徑上的節點數據也存儲在賬本數據中)
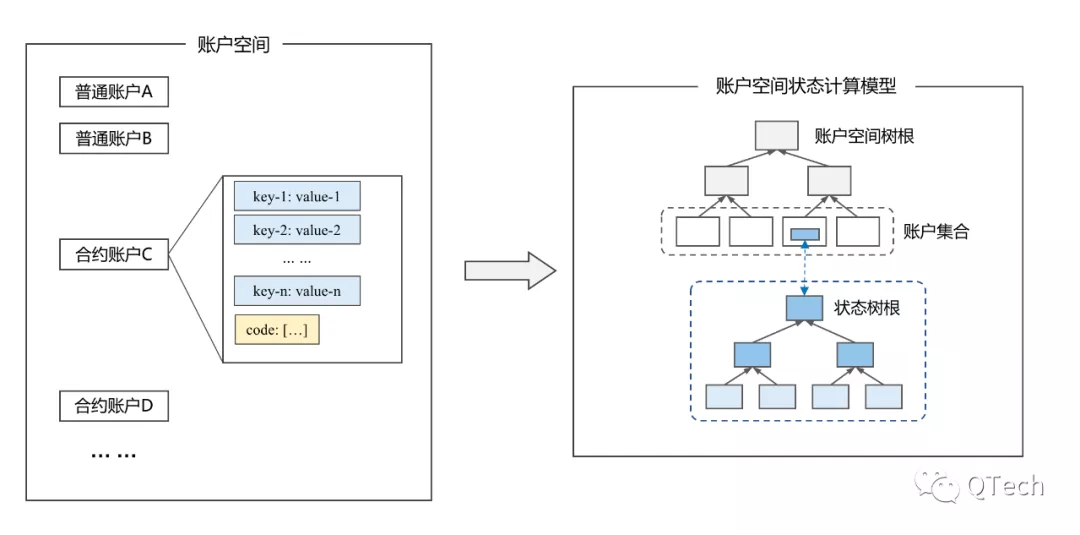 圖片
圖片
交易執行結果/回執數據
“UTXO模型” 的系統交易執行結果比較直接,所有的合法交易的執行結果就是成功標識+ “交易輸出” 內容;所有非法交易的執行結果就是失敗標識,而交易的輸入部分保持原狀。
但是“賬戶模型” 的區塊鏈系統中,一般會包含轉賬交易和智能合約調用交易。交易的執行結果一般要經過虛擬機執行得到,考慮合約調用的場景,交易的執行結果很可能並不體現在交易內容和賬戶空間變更結果中;因此,交易的回執數據需要獨立存儲,為了統一賬戶創建、賬戶間轉賬、智能合約調用等多種交易的執行結果,系統一般會設計統一的回執數據組織格式。
至此,交易數據+賬戶空間+交易執行結果三者一同構成了賬戶模型下的系統的最基本的世界狀態。相應的,這類系統中的存儲模塊,需要提供這三類數據的存儲功能。在具體設計和實現存儲模塊時,可以結合區塊鏈系統的運作模式,綜合考慮吞吐量和延遲等指標,根據不同數據的業務特點設計和使用不同的底層存儲引擎。
索引數據
一個完整的區塊鏈系統除了提供上述寫入功能外,還需要提供歷史數據的查詢功能。如果系統中只存儲了上述世界狀態數據,那麼用戶對歷史數據的查詢只能通過遍歷所有區塊實現,這樣的代價和延遲很顯然是無法接受的。
因此,一般的區塊鏈系統都會考慮設置一種基本的索引——交易索引。藉由這種索引,系統能夠快速的確認交易所在的區塊,甚至可以更細粒度的直接定位到交易存儲於這個區塊內的哪個位置。索引的內容一般就是“交易哈希(交易標識)”到“交易所在位置”的映射。
這樣的索引設計會給系統持久化區塊的過程帶來一定的“寫放大” ,單無論從數據量還是從必要性角度出發,一般的區塊鏈系統都會選擇接受這種代價。
【區塊鏈存儲相關的“一致性”】
至此,一個簡單通用的區塊鏈系統必要的存儲內容已經介紹完畢。但是這還不是區塊鏈系統的存儲模塊需要考慮的全部內容。在區塊鍊網絡中,所有誠實節點在相同的區塊執行完畢後,需要擁有完全一致的世界狀態。這個世界狀態可以由區塊確認後的“區塊哈希”表示。
但是,區塊鏈系統一般會運行在一個拜占庭網絡環境中;那麼,區塊鏈系統隨時存在著數據落後的情況,整個網絡也存在著隨時新增和刪除節點的情況。無論是落後的誠實節點,還是新增進入網絡的誠實節點,都需要盡快追趕上網絡中的其他誠實節點。
那麼落後的節點如何“追趕” 其他的誠實節點呢?這裡我們再重新審視一下“交易” 這個角色。前文提到:“區塊鏈系統的整體數據狀態是依賴交易的執行而不斷向後演進的”,那麼交易就可以看作是區塊鏈系統世界狀態變更的“日誌” 。
基於這樣的理解角度,落後節點“追趕” 其他誠實節點可以通過同步誠實節點的區塊來實現,因為區塊中的區塊體包括了全量的交易內容,那麼落後節點可以通過重放其缺少交易,最終達到與其他節點一致的世界狀態。這個恢復的過程,落後節點不需要參與共識,而是藉由一系列校驗協議來確保數據的完整性和正確性。
進一步分析上述交易重放流程,如果是UTXO模型的系統,交易的內容和執行過程比較簡單;但是對於賬戶模型的系統,則交易可能是合約執行請求,那麼執行這筆交易的過程就不可避免的會涉及執行環境的創建,使用虛擬機執行完整的合約指令等等步驟。那麼,對於節點間網絡環境較好的場景,是不是有進一步提高落後節點“追趕”速度的策略呢?
由此,在特定的場景下,比如“聯盟鏈+賬戶模型” 的系統中,數據同步的過程可以引入另一種策略:如果在交易執行的過程中,系統將所有的賬本數據(也就是賬戶空間)修改相關的操作都記錄下來,形成一份賬本操作日誌數據(可以類比MySQL中Binlog的row模式思路);那麼在做數據同步時,落後節點可以直接拉取區塊數據、賬本操作日誌數據和交易回執數據,完成後並將拉取賬本操作日誌數據按序應用到本地賬本數據上,完成應用日誌的過程後,落後節點便完成了與其他誠實節點一致的“世界狀態”的構建。
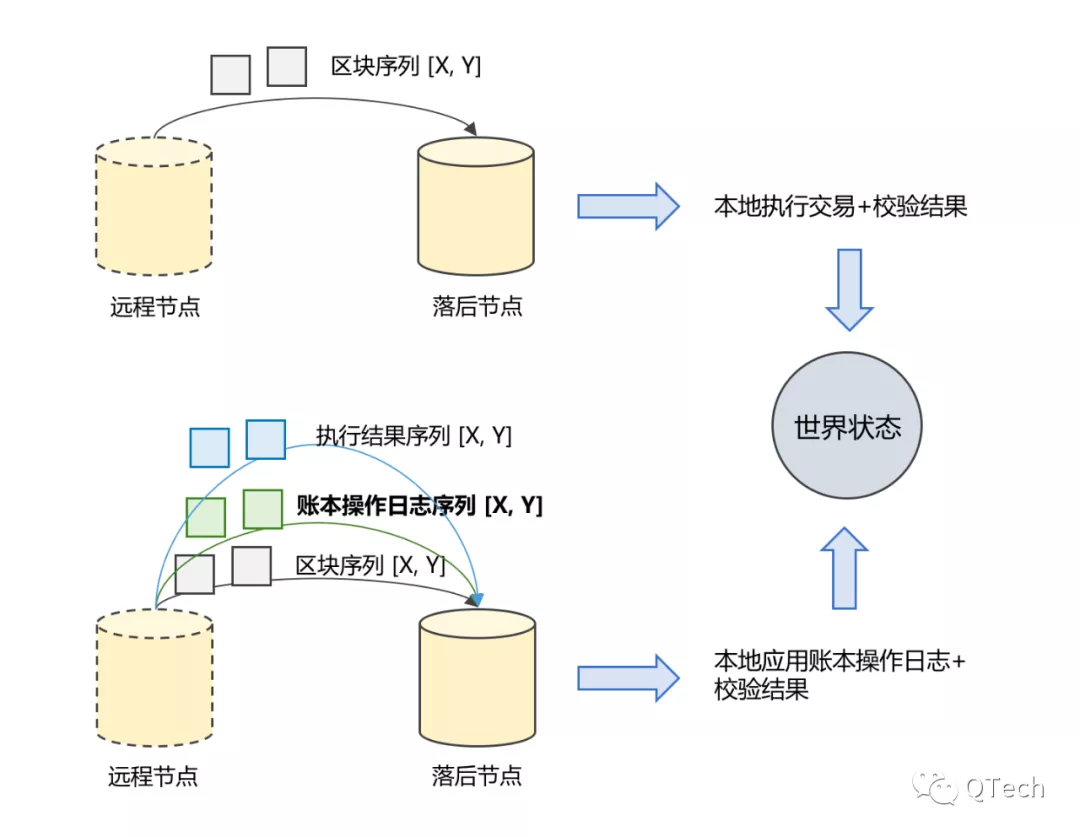 圖片
圖片
基於上述思路,存儲模塊可以引入另一種與世界狀態有關的數據——操作日誌數據,這些數據與交易的執行過程強相關。在某些網絡帶寬充裕、智能合約計算邏輯複雜但賬本數據修改不頻繁的場景下,上述思路是一種有效加速節點間數據同步的解決方案。
【小結與思考】
至此,本文第一個引入的“區塊鏈存儲模塊是不是數據庫” 的問題,可以做一個簡單的總結:筆者認為,數據庫和區塊鏈存儲是可以區分開來看待的概念,區塊鏈存儲模塊無論從功能邊界、服務對像還是自身的拓展優化思路上,都是和“區塊鏈系統” 這個場景強相關的。本系列後續的文章會針對區塊鏈系統的內部邏輯和場景,分別討論各種數據的存儲模式和存儲設計思路。但是OLTP數據庫系統,其考慮的場景則是一個更寬廣、更通用的層面。
最後,可能部分讀者會思考這樣一個問題:本文一直在強調“區塊鏈存儲系統的專用性和為區塊鏈場景定制” 的思路,那在現實業務場景使用區塊鏈底層平台時,平時常聽到的“通用型平台” 這個概念又該如何理解呢?
其實,“為區塊鏈系統的內部運作機理提供定制化的存儲模塊功能” ,與“區塊鏈系統整體對外提供通用的業務支持” ,是兩個層面的問題,兩者並不矛盾。本文討論的存儲模塊的定制化,專用性,是針對區塊鏈系統的內部運行邏輯定制化的設計存儲功能,但是區塊鏈系統中賬本組織模型的設計和智能合約功能的存在,則允許用戶為多種業務場景自定義合約邏輯、自定義賬本“狀態數據” 。
作者簡介
郭威趣鏈科技基礎平台部區塊鏈存儲研究小組
參考文獻
[1] https://github.com/ethereum/go-ethereum
[2] https://github.com/hyperledger/hyperledger
[3] https://developer.confluxnetwork.org/
[4] 《精通比特幣第二版》
展開全文打開碳鏈價值APP 查看更多精彩資訊