
作者:Abel Chan
隨著最近Ceramic、IPFS和Arweave等工具的發展,一個更加去中心化的互聯網架構正在慢慢出現,數據被存儲在個人數據商店而不是企業服務器或中心化雲服務中。個人數據存儲意味著用戶將首次能夠完全擁有他們的數據,控制他們的數據如何被使用,並在他們的數據價值中獲得更大份額。隨著來自不同應用程序的數據在用戶的控制下存儲在一起,應用程序之間的低摩擦數據共享也應導致更大的可組合性和比目前更豐富的應用程序生態系統。
儘管這個願景很有希望,但轉向以用戶為中心的數據所有權模式是一個重大變化,不會在一夜之間發生。值得探討的是,從現在的情況開始,事情會如何發展。
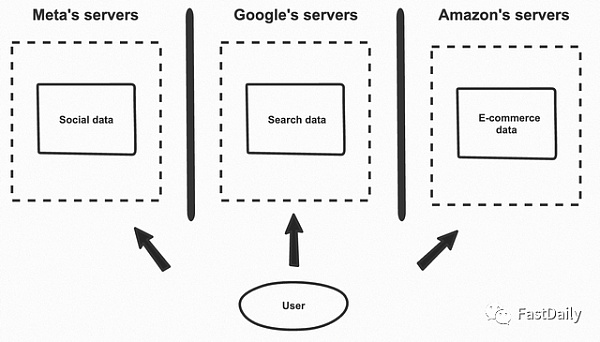
今天的數據存儲在公司服務器上的孤島中
今天,如果一個用戶正在瀏覽一個網站,他們產生的數據會被儲存在兩個主要位置——瀏覽器和公司擁有的數據庫。如果你在Facebook註冊並創建一個賬戶,那麼關於你的賬戶和第一篇文章的數據將直接進入Meta的服務器。如果你再去創建一個Gmail的賬戶,那麼就會被單獨存儲在谷歌的服務器上。這種方法被稱為以應用為中心的數據存儲模式。
由於數據被公司存儲在不同的數據庫中,所以對數據的使用方式幾乎沒有直接控制。它可以被複製,用於未經授權的目的,或在你不知情或不同意的情況下轉售,儘管像GDPR和CCPA這樣的法規在一定程度上有所幫助。用戶也很難在應用程序之間共享數據。如果你是一個開發者,你可以得到用戶的憑證,然後在幕後做一個API集成來獲取數據(例如,集成Plaid來連接Chase),但這不是一個小的工作量。
“數據艙“為使用鏈外數據的dapp提供可組合性
至少從2017年開始,互聯網的發明者Tim Berners Lee一直在開發以用戶為中心的數據存儲模型。根據這一設想,個人應該能夠選擇他們的數據所處的位置以及誰可以訪問這些數據。在Web3中,這意味著將數據存儲在與創建它的用戶相關的IPFS等服務上,而不是基於創建它的應用程序的企業服務器上1。請注意,像AWS或谷歌云這樣的中心化雲服務並不符合“個人數據存儲“的要求,因為亞馬遜和谷歌仍然可以不受限制地訪問用戶數據。相比之下,通過使用像Ceramic這樣的服務與去中心化的存儲相結合,數據可以被加密,其訪問由用戶使用加密密鑰管理,因此除了用戶之外,沒有人可以未經許可進行互動。
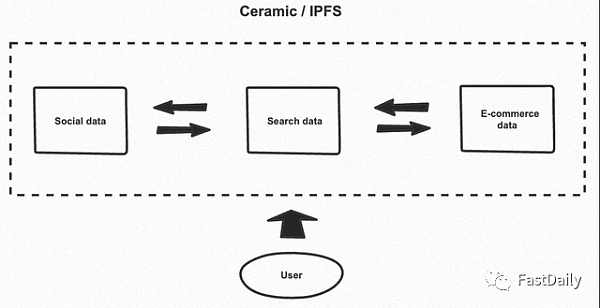
個人數據存儲通過將數據存儲在一個地方來提高可組合性
對於使用個人數據存儲的可能性的例子,假設你使用Sign In With Ethereum(SIWE)來登錄一個去中心化的社交媒體應用程序。你與該應用的互動然後進入你的個人數據存儲。後來當你登錄到一個去中心化的市場時,你分享了對存儲在你的“數據艙“中的社交媒體的訪問,並收到基於這些的定制推薦。使用包含在你的“pod”中的所有網站的可訪問索引,市場應用甚至可能發現你在Adidas.com上的賬戶,並為你提供折扣的運動鞋。
通過這種設置,用戶可以輕鬆地管理哪些數據將與誰共享。用戶今天用來授權訪問他們的谷歌數據的相同流程,可以被用戶重新利用來授權訪問他們的任何或所有的DApp數據。如果用戶不想分享,而只是想刪除他們的所有數據,這種模式也可以讓他們完全控制,做出這個決定。
使用Google 登錄請求用戶權限
在另一邊,想讓用戶分享數據或訪問dapp數據的開發者可以不用處理自定義API集成。相反,一個通用的登錄服務(如SIWE)和“數據艙“可以結合起來,形成一個可重複使用的模式來授予數據訪問權。這就好比即使是世界上最小的創業公司也可以實現自己的谷歌登錄來對外分享數據,或者使用谷歌登錄來訪問任何其他公司的數據。
這樣做的最終結果應該是更大的可組合性。雖然數據的可訪問性很少影響使用鏈上數據的應用程序的可組合性,但由於區塊鏈數據是透明的,對於利用敏感的鏈下數據的應用程序來說,這可能是一個問題,必須仔細許可以保護用戶隱私。使用通用登錄解決方案(例如SIWE)來授予對這個個人“數據pod”中的隔間的訪問權限解決了這個問題,並允許使用鏈下數據的dapp 更輕鬆地進行交互。
除了可組合性,還有數據所有權
一個典型的美國谷歌用戶每年的數據被貨幣化為256美元,而一個典型的美國Meta用戶的數據是1122美元。儘管科技公司目前通過收集用戶產生的大量數據然後將其貨幣化來創造收入,但如果我們採用以用戶為中心而不是以應用為中心的數據存儲模式,這種方法就會發生變化。
今天,有兩種主要的數據用於廣告:第一方數據,由用戶正在訪問的網站收集,以及第三方數據,由用戶當前網站以外的其他方收集。第一方數據可能是非常詳細和有價值的,但很難獲得,因為它必須由用戶直接提供3。第一方數據的一個例子是在註冊時提交的賬戶信息,或者你在電子商務網站上填寫的調查。另一方面,第三方數據更為廣泛,但也更為淺顯。谷歌的第三方cookie可以在你瀏覽各個網站時跟踪你的URL,甚至當你在非谷歌網站時,也可以與穀歌分享數據。這種數據有廣度,但沒有深度,因為URL並不包含關於用戶的更多細節。
廣告技術行業的一個核心問題是與跨瀏覽器和設備追踪人有關。由於大量用於追踪的cookies不能在不同的瀏覽器上跟踪人們,即使是在同一設備上,如果用戶不登錄或提交他們的電子郵件,就很難知道他們是誰。零散的數據價值較低。假設你在耐克公司工作——如果你知道John早些時候在火狐桌面上訪問了adidas.com,但你不知道目前在iPhone上訪問合作夥伴網站的人也是John,那麼你剛剛錯過了展示運動鞋廣告的機會。由於第三方cookies已經在Firefox以及Opera上被禁止,並將在2024年之前從Chrome中移除,因此跨設備追踪用戶只會變得更加困難。
如果第三方數據越來越不可靠,那麼第一方數據自然是一個可以考慮的替代方案。即使假設像《紐約時報》這樣的網站願意出售其登錄用戶閱讀和評論的故事的數據,也沒有簡單的方法來做到這一點。因為沒有技術框架,所以需要手工操作,以使數據能夠被外部各方訪問,並接受數據的付款。
Web3的數據將更容易獲取和標準化
正如存儲在個人數據商店的數據的開放性、可訪問性和可發現性增加了可組合性一樣,它也為數據的貨幣化帶來了巨大的潛在改進。同樣的“用X登錄“模式可以被開發者用來獲取數據用於開發目的,也可以被廣告商和用戶用來交換數據並實現貨幣化。
解決當今明顯的行業問題,以用戶為中心的數據存儲將使跨設備追踪用戶變得相當容易,只要他們使用像Sign in With Ethereum這樣的去中心化身份解決方案進行登錄。從中期來看,個人數據存儲所提供的改進的技術框架和貨幣化潛力也將使大量高質量的第一方數據變得可用。像Meta或谷歌這樣的公司存儲在其服務器上的所有數據,理論上都有可能在個人數據存儲中提供,但要考慮隱私問題、存儲限制和其他技術因素。
然而,從長遠來看,改善開放數據標準的潛力可以使今天在混亂的數據中掙扎的工程師、數據科學家和數據工程師的生活變得容易得多。如果大量今天不透明的“專有“數據集能夠被公開訪問(儘管可能需要付費),那麼無論是通過直接協調還是人們複製他人正在做的事情,都會更容易匯聚到數據標准上。想像一下用於存儲電子商務數據、金融交易數據、證書等的標準化格式並不難。擁有一個以用戶為中心的數據存儲模型,不僅會讓用戶的生活變得更好,也會讓開發者和廣告商的生活變得更加輕鬆。
然而,最重要的是,假設有更多的第一方數據可用,並使廣告商得到更好的服務,用戶最終會要求獲得更大但仍可持續的數據價值份額。像Brave這樣的公司已經開始給用戶提供他們所看到的廣告的收入份額,但這還可以更進一步。如果用戶願意選擇分享更高質量的數據,就會有更多有價值的數據,然後用戶就可以從中抽成(如Brave Rewards),而每個人都會得到更好的回報。然而,關鍵是用戶的選擇。許多用戶無疑重視他們的隱私,但對於那些喜歡其他方式的用戶可以選擇捕捉他們自己的數據價值而不是隱私。
如果Web3基本上只是更多的廣告,但用戶獲得更大的價值份額,這當然不是一個壞的起點。然而,我們仍然可以做得更好,考慮用更聰明的方式來獲取數據的價值。
建立一個全球數據市場
與其讓用戶受制於今天的廣告,我們可以選擇讓用戶直接出售他們的數據。這些數據市場今天已經存在,但大多涉及第三方和數據經紀人在灰色市場上出售數據,而沒有用戶的可見性或授權。
未來的數據市場可以在開放源碼中實現,並內置隱私控制。如果來自用戶的數據主要託管在個人數據商店,你可以設想一個統一的市場,它包含對互聯網上大多數用戶數據的訪問。用戶可以選擇他們可以出售的數據,以及他們接受的數據的最低金額。營銷人員可以搜索符合特定屬性的用戶,或特定應用程序的用戶。學術研究人員可以帶著預算來,在幾分鐘內從他們的具體研究項目中獲得有針對性的數據集。
在線市場理論上並不難建立,它們已經存在了很久(想想Craigslist)。然而,對於個人數據市場來說,有幾個獨特的問題需要解決。第一個問題相當簡單:一旦數據被出售,它就脫離了用戶的控制,可以被無限地複制。你可以在一定程度上避免這個問題,對於經常性非常重要的數據(例如,你最近訪問過哪些網站),但其他類型的數據幾乎肯定會被轉賣。保護隱私的技術在這方面提供了一些解決方案,我們將在後面討論。
擁有可用數據的公司或應用程序也需要一些激勵措施來放棄對用戶數據的控制,並有可能要求獲得數據銷售的百分比。這對於用戶擁有的數據來說似乎不合適,但請記住,A)他們目前在數據貨幣化收入中的份額是100%,這比說5%要大;B)如果沒有數據源的參與,用戶就沒有什麼可供貨幣化的。如果你是一個市場,你需要供應需求。公司也會要求在一定程度上控制數據被賣給誰。耐克不希望他們最有價值的用戶數據被阿迪達斯廉價購買。有些公司根本不買賬,有些公司會提供一些數據,而有些公司會完全接受開放數據交換。
最後,要弄清楚如何為數據定價可能會很棘手。數據的價值不僅取決於你所購買的數據,還取決於你已經有多少數據與之結合以訓練一個模型,以及你使用這些數據的目的。大多數人都不知道如何給他們的數據定價,所以我們需要好的建議,以多少錢來出售數據。關於數據定價的更多信息,請參見Ocean Protocol45的腳註中的優秀資源。
每個人都討厭廣告,但沒有人願意真正付費
完全擺脫廣告,僅通過用戶出售數據來支持Web3是否可行?這似乎不太可能,因為許多公司購買數據的目的很可能是為了服務廣告。此外,廣告如此廣泛存在有一個根本原因。
為什麼今天會有廣告存在?調查顯示,75%的美國人認為在線廣告具有侵擾性6。在超級碗廣告之外,幾乎沒有人喜歡廣告。
簡單的答案是,高質量的內容和服務需要錢來製作。 《紐約時報》有5000名員工,谷歌有一些員工團隊在為他們的免費地圖產品改進算法,這些都是免費的。在一個可以選擇付費的網站上,估計只有1-3%的用戶會選擇付費7。即使是那些願意付費的人,一些內容或網站的價值(例如你前幾天讀到的那個簡短的體育故事)可能只值這麼一點錢(例如0.10美元),所以不值得花精力去做小額支付。由於這些原因,Web2.0已經默認了廣告的使用,以支付從有趣的Buzzfeed故事到Tiktok短視頻的免費服務。
Web3已經提出了新的貨幣化選擇,但沒有一個能解決95%不想付費的用戶的關鍵問題。對於內容創作者或媒體公司來說,NFT絕對是有價值的工具,但這些很可能只被高度參與的粉絲購買。他們不會幫助捕捉其他95%參與度較低、不想購買的粉絲。微額支付很好,但可能仍然會失敗,原因與Web 2.0相同,因為它們所涉及的努力對於小交易額(例如0.10美元)來說是不值得的。相比之下,無論用戶是否點擊,廣告都會被顯示並為網站創造收入。
每個人都討厭廣告。但沒有人討厭到要真正付錢的地步。如果Web3不能找到從數據中實現價值的方法,它將沒有現實的機會參與競爭。
聯合學習保護隱私
如果廣告是一種必要的邪惡,我們如何才能在Web3中使其變得更好?這就把我們帶到了最後的討論,保護隱私的廣告。
Brave瀏覽器是加密領域的先驅,以其註重隱私的瀏覽器而聞名,它阻止了大多數傳統的廣告,以及其保護隱私的廣告。作為一個瀏覽器,Brave可以訪問瀏覽歷史等數據,這些數據有一天可能會被儲存在個人數據艙中。為了取代它所屏蔽的傳統廣告,Brave瀏覽器以瀏覽器通知的形式向用戶展示選擇廣告。瀏覽這些選擇廣告的用戶會因此獲得獎勵。有趣的是,Brave還運行一個“廣告網絡”,廣告商可以購買針對對特定主題感興趣的用戶的廣告,如“體育”、”購物“或“旅遊”。
Brave的廣告是獨特的,因為它使用保護隱私的機器學習來決定顯示哪些廣告。 Brave利用一種稱為“聯合學習“的特殊技術來訓練他們的廣告模型,預測用戶最有可能點擊的廣告。通過聯合學習,一個模型的“小塊“首先在用戶的設備上用他們自己的數據進行訓練,然後這個“小塊“被發送到一個中央服務器,與其他小塊結合,形成一個最終模型。與穀歌等公司使用的技術相比,這些公司的廣告模型通常是在服務器或服務器集群中集中存放的大量數據上進行訓練的,這種技術確保沒有私人數據離開用戶的設備8。這個想法是,如果沒有私人數據離開用戶的設備,那麼他們的數據就會受到保護,不會在未經他們允許的情況下被轉售或利用。仍然有一些隱私問題需要解決,例如,看一個用戶的模型可能會告訴你一些關於他們的數據是什麼樣子。但最終,只要最終的模型有足夠的預測性,這種設置仍然比現狀的隱私好很多。
在一個所有用戶的數據都可以在個人數據艙中獲得的世界中,大量的數據將提供給所有各方(不僅僅是特定的公司),而且更多的模型,不僅僅是廣告模型,可以安全地在這些數據上訓練。想想醫療保健的模型,根據病人的醫療數據訓練,而不是預測人們點擊廣告的模型。
技術的現狀
我們離實現這個願景還有多遠?
去中心化的存儲層已經到位了。像IPFS和Arweave這樣的不可變的存儲服務已經分別存在了7年和5年,並且正在迅速成熟起來。請注意,這些數據存儲必須是不可變的,因為在一個去中心化的環境中,必須注意數據不被篡改。在這些之上,像Ceramic或Textile的ThreadsDB這樣的工具增加了一個“可變性“層,通過在不可變的存儲之上實現一個只需追加的分類賬910,使修改數據變得更加容易。儘管賬本中的每一個額外的更新都是不可變的,但解析綜合更新的最終結果是可變的,就像比特幣賬戶餘額可以改變一樣,儘管單個過去的交易是不可變的。
隱私和許可功能是仍然可以使用進一步發展的領域。 Ceramic似乎最近才實施許可系統,它可能仍然需要一些時間來成熟和變得完全強大11。對於隱私敏感的用戶來說,在用戶的個人設備上實現數據艙,而不是在第三方的分散存儲節點上實現,可能是有用的。對於在手機和電腦等個人設備上實現的數據存儲,數據可能會根據需要在線或離線,而且對存儲節點是否真的刪除或以其他方式複制了你的數據的擔心會減少。幫助獲取數據價值的附加層在很大程度上似乎還沒有被開發出來。專注於簡單的數據交換和貨幣化的協議可能是一個好的起點。除此之外,必須創建去中心化的數據市場或實現個人數據存儲的聯合學習協議。
與技術一起考慮的最後一塊缺失是監管。儘管如果用戶要求,公司可以採用個人數據存儲,但不能強迫他們不在其它地方存儲額外的數據副本。類似於GDPR(通用數據保護條例)的未來法律,是歐盟關於數據隱私的法律,可以強制執行更好的行為,並加速企業採用個人數據存儲作為遵守隱私法規的更簡單的方法。這些法規,如個人數據存儲,可以成為強大的工具,幫助確保數據隱私(和數據所有權)作為用戶的基本權利。
引用:
https://inrupt.com/solid/
https://mondaynote.com/the-arpus-of-the-big-four-dwarf-everybody-else-e5b02a579ed3
https://www.thetradedesk.com/us/news/what-the-tech-is-first-and-third-party-data
https://blog.oceanprotocol.com/lets-talk-about-data-pricing-part-i-bbc9cf781d9f
https://blog.oceanprotocol.com/value-of-data-part-two-pricing-bc6c5127e338
https://arxiv.org/pdf/2104.14362.pdf
https://docs.textile.io/threads/
https://developers.ceramic.network/learn/advanced/overview/
https://blog.ceramic.network/capability-based-data-security-on-ceramic/
