

過去幾個月,我們投入了大量時間和精力,開發了利用zk-SNARK 簡潔證明構建的前沿基礎設施。這個下一代創新平台使開發者能夠構建前所未有的區塊鏈應用新範例。
在開發工作中,我們測試並使用了多種零知識證明(ZKP) 開發框架。雖然這段旅程收穫頗豐,但我們也確實意識到,當新的開發者試圖找到最適合其特定用例和性能要求的框架時,多種多樣的ZKP 框架通常會給他們帶來挑戰。考慮到這一痛點,我們認為需要一個能夠提供全面性能測試結果的社區評估平台,這將極大地促進這些新應用的開發。
為了滿足這一需求,我們推出了零知識證明開發框架評測平台「萬神殿Pantheon」 這一公益社區倡議。倡議的第一步將鼓勵社區分享各種ZKP 框架的可複現性能測試結果。我們的最終目標是共同協作創建並維護一個廣受認可的測試平台,評估低級電路開發框架、高級zkVM 和編譯器,甚至硬件加速提供商。我們希望這一舉措能夠讓開發者們在選用框架時能有更多性能比較的參考,從而加快ZKP 的推廣。同時,我們希望通過提供一組普遍可參考的性能測試結果,促進ZKP 框架本身的升級和迭代。我們將大力投入這項計劃,並邀請所有志同道合的社區成員加入我們,共同為這項工作做出貢獻!
第一步:使用SHA-256 對電路框架進行性能測試
在這篇文章中,我們邁出了構建ZKP Pantheon 的第一步,在一系列低級電路開發框架中使用SHA-256 提供一組可複現的性能測試結果。雖然我們承認其他性能測試粒度和原語或許也是可行的,但我們選擇SHA-256 是因為它適用於廣泛的ZKP 用例,包括區塊鏈系統、數字簽名、zkDID 等。
另外值得一提的是,我們在自己的系統中也使用了SHA-256,所以這對我們來說也很方便! 😂
我們的性能測試評估了SHA-256 在各種zk-SNARK 和zk-STARK 電路開發框架上的性能。通過比較,我們力求為開發者提供關於每個框架的效率和實用性的見解。我們的目標是,希望本次性能測試結果能夠為開發者在選擇最佳框架時提供參考,使之做出明智的決定。
證明系統
近年來,我們觀察到零知識證明系統激增。跟上該領域所有激動人心的進步是具有挑戰性的,我們根據成熟度和開發者採用情況精心挑選了以下證明系統作為測試對象。我們的目標是提供不同前端/後端組合的代表性樣本。
-
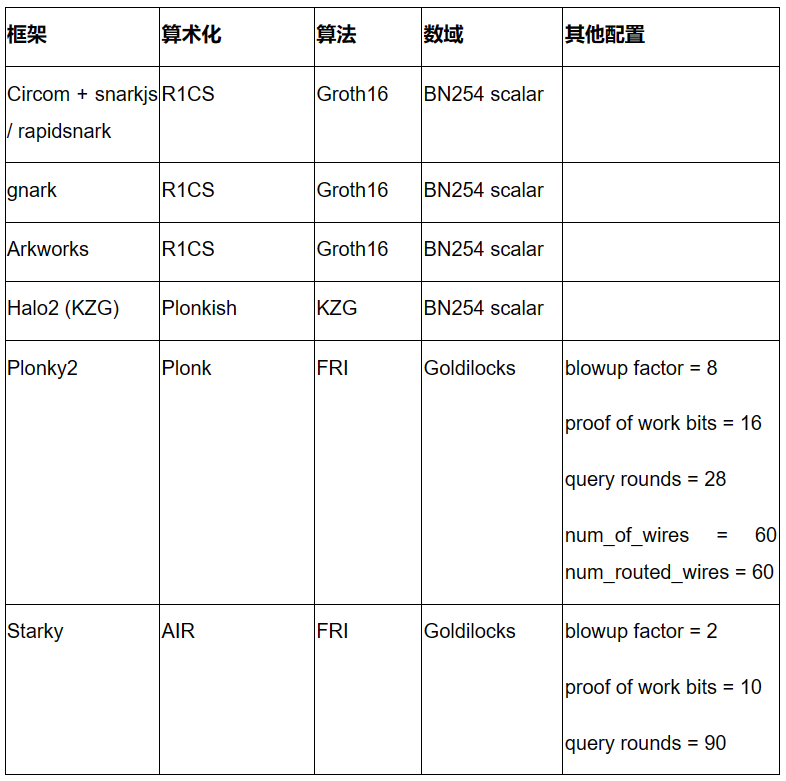
Circom + snarkjs / rapidsnark: Circom 是一種流行的DSL,用於編寫電路和生成R1CS 約束,而snarkjs 能夠為Circom 生成Groth16 或Plonk 證明。 Rapidsnark 也是Circom 的證明器,它生成Groth16 證明,並且由於使用了ADX 擴展,它通常比snarkjs 快得多,並儘可能並行化證明生成。
-
gnark: gnark 是來自Consensys 的綜合Golang 框架,支持Groth16、Plonk 和許多更高級的功能。
-
Arkworks: Arkworks 是一個用於zk-SNARKs 的綜合Rust 框架。
-
Halo2 (KZG): Halo2 是Zcash 與Plonk 的zk-SNARK 實現。它配備了高度靈活的Plonkish 算術,支持許多有用的原語,例如自定義網關和查找表。我們使用具有以太坊基金會和Scroll 支持的KZG 的Halo2 分叉。
-
Plonky2: Plonky2 是基於來自Polygon Zero 的PLONK 和FRI 技術的SNARK 實現。 Plonky2 使用小的Goldilocks 字段並支持高效的遞歸。在我們的性能測試中,我們以 100 位推測的安全性為目標,並使用為性能測試工作產生最佳證明時間的參數。具體來說,我們使用了28 Merkle 查詢、8 的放大係數和 16 位工作量證明挑戰。此外,我們設置num_of_wires = 60 和num_routed_wires = 60。
-
Starky: Starky 是Polygon Zero 的高性能STARK 框架。在我們的性能測試中,我們以 100 位推測的安全性為目標,並使用產生最佳證明時間的參數。具體來說,我們使用了90 Merkle 查詢、2 倍放大係數和10 位工作量證明挑戰。
下表總結了上述框架以及我們性能測試中使用的相關配置。這個列表絕不是詳盡的,我們還將在未來研究許多最先進的框架/技術(例如,Nova、GKR、Hyperplonk)。
請注意,這些性能測試結果僅適用於電路開發框架。我們計劃在未來發布一篇單獨的文章,對不同的zkVM(例如,Scroll、Polygon zkEVM、Consensys zkEVM、zkSync、Risc Zero、zkWasm)和IR 編譯器框架(例如,Noir、zkLLVM)進行性能測試。
性能評測方法論
為了對這些不同的證明系統進行性能測試,我們計算了N 字節數據的SHA-256 哈希值,其中我們對N = 64、128、…、64K 進行了實驗(Starky 是一個例外,其中電路重複SHA-256 固定64 字節輸入的計算,但保持相同的消息塊總數)。可以在此存儲庫中找到性能代碼和SHA-256 電路配置。
此外,我們使用以下性能指標對每個系統進行了性能測試:
- 證明生成時間(包括見證生成時間)
- 證明生成期間的內存使用峰值
- 證明生成期間的平均CPU 使用率百分比。 (該指標反映了證明生成過程中的並行化程度)
請注意,我們正在對證明大小和證明驗證成本做一些“隨意”的假設,因為這些方面可以通過在上鍊之前與Groth16 或KZG 組合來減輕。
機器
我們在兩台不同的機器上進行了性能測試:
- Linux 服務器:20 核@2.3 GHz,384GB 內存
- Macbook M1 Pro:10 核@3.2Ghz,16GB 內存
Linux 服務器用於模擬CPU 核數多、內存充裕的場景。而通常用於研發的Macbook M1 Pro 擁有更強大的CPU,但內核較少。
我們啟用了可選的多線程,但我們沒有在此性能測試中使用GPU 加速。我們計劃在未來進行GPU 性能測試。
性能評測結果
約束數量
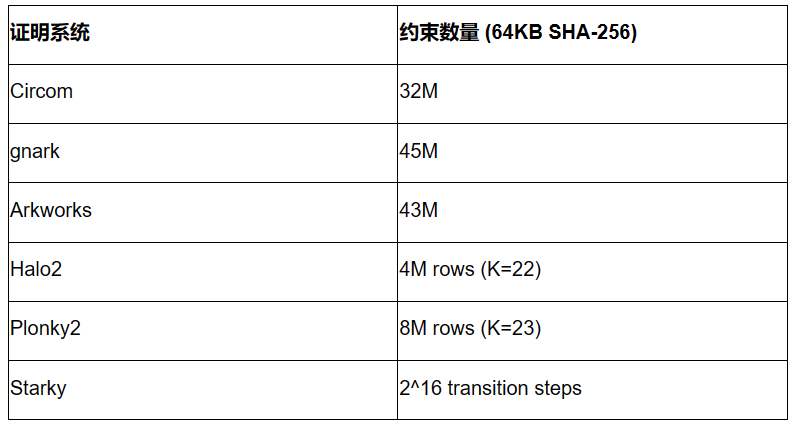
在我們繼續討論詳細的性能測試結果之前,首先通過查看每個證明系統中的約束數量來了解SHA-256 的複雜性是很有用的。重要的是要注意不能直接比較不同算術方案中的約束數量。
下面的結果對應64KB 的原像尺寸。雖然結果可能因其他原像尺寸而異,但它們可以粗略地線性縮放。
- Circom、gnark、Arkworks 都使用相同的R1CS 算法,計算64KB SHA-256 的R1CS 約束數量大致在30M 到45M 之間。 Circom、gnark 和Arkworks 之間的差異可能是由於配置差異造成的。
- Halo2 和Plonky2 都使用Plonkish 算術,其中行數範圍從2^22 到2^23。由於使用查找表,Halo2 的SHA-256 實現效率比Plonky2 的高得多。
- Starky 使用AIR 算法,其中執行跟踪表需要2^16 個轉換步驟。
證明生成時間
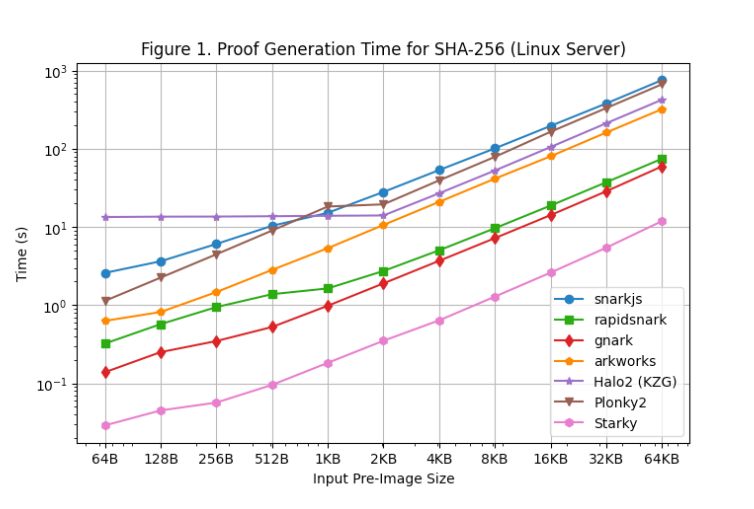
[图 1] 使用Linux 服務器測試了SHA-256 的每個框架在各種原圖像尺寸上的證明生成時間。我們可以得到以下發現:
- 對於SHA-256,Groth16 框架(rapidsnark、gnark 和Arkworks)生成證明的速度比Plonk 框架(Halo2 和Plonky2)快。這是因為SHA-256 主要由位運算組成,其中線值為0 或1。對於Groth16,這減少了從橢圓曲線標量乘法到橢圓曲線點加法的大部分計算。但是,連線值並不直接用於Plonk 的計算,因此SHA-256 中的特殊連線結構不會減少Plonk 框架中所需的計算量。
- 在所有Groth16 框架中,gnark 和rapidsnark 比Arkworks 和snarkjs 快5 到10 倍。這要歸功於它們利用多個內核並行化生成證明的卓越能力。 Gnark 比rapidsnark 快25%。
- 對於Plonk 框架,當使用>= 4KB 的較大原像尺寸時,Plonky2 的SHA-256 比Halo2 的慢50%。這是因為Halo2 的實現主要使用查找表來加速按位運算,導致行數比Plonky2 少2 倍。但是,如果我們比較具有相同行數的Plonky2 和Halo2(例如,Halo2 中超過2KB 的SHA-256 與Plonky2 中超過4KB 的SHA-256),Plonky2 比Halo2 快50%。如果我們在Plonky2 中使用查找表實現SHA-256,我們應該期望Plonky2 比Halo2 更快,儘管Plonky2 的證明尺寸更大。
- 另一方面,當輸入原像尺寸較小(<=512 字節)時,由於查找表的固定設置成本佔大部分約束,Halo2 比Plonky2(和其他框架)慢。然而,隨著原像的增加,Halo2 的性能變得更具競爭力,對於高達2KB 的原像大小,其證明生成時間保持不變,如圖所示,其幾乎呈線性擴展。
- 正如預期的那樣,Starky 的證明生成時間比任何SNARK 框架都短得多(5倍-50倍),但這是以更大的證明大小為代價的。
- 另外需要注意的是,即使電路大小與原像大小成線性關係,由於O(nlogn) FFT,對於SNARKs 的證明生成也是呈超線性增長的(儘管由於對數刻度,這一現像在圖表上並不明顯)。
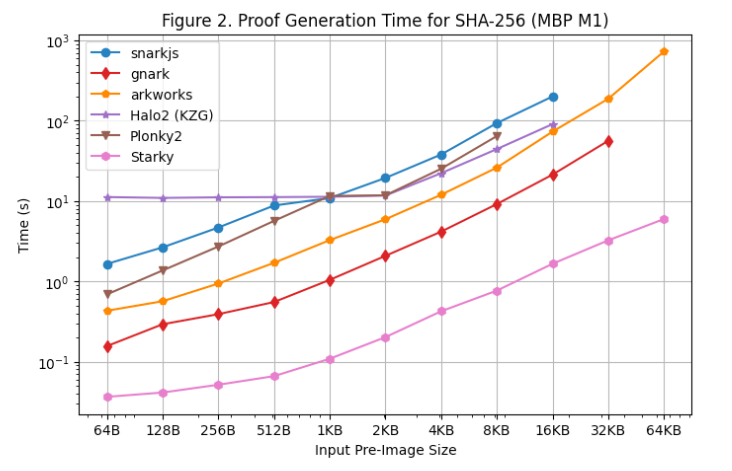
我們還在Macbook M1 Pro 上進行了證明生成時間性能測試,如 [图 2] 所示。但是,需要注意的是,由於缺乏對arm64 架構的支持,rapidsnark 未包含在該性能測試中。為了在arm64 上使用snarkjs,我們必須使用webassembly 生成見證,這比Linux 服務器上使用的C++ 見證生成要慢。
在Macbook M1 Pro 上運行性能測試時還有幾個額外的觀察結果:
- 除了Starky 之外,所有SNARK 框架在原像尺寸變大時都會遇到內存不足(OOM) 錯誤或使用交換內存(導致證明時間變慢)現象。具體來說,Groth16 框架(snarkjs、gnark、Arkworks)在原像尺寸>= 8KB 時就開始使用交換內存,而gnark 在原像尺寸>= 64KB 時出現內存不足。當原像尺寸>= 32KB 時,Halo2 遇到了內存限制。當原像尺寸>= 8KB 時,Plonky2 開始使用交換內存。
- 基於FRI 的框架(Starky 和Plonky2)在Macbook M1 Pro 上比在Linux 服務器上快大約60%,而其他框架在兩台機器上面的證明時間相似。因此即使在Plonky2 中沒有使用查找表,它在Macbook M1 Pro 上實現了與Halo2 幾乎相同的證明時間。主要原因是Macbook M1 Pro 擁有更強大的CPU,但內核更少。 FRI 主要進行哈希運算,對CPU 時鐘週期比較敏感,但並行性不如KZG 或Groth16。
內存使用峰值
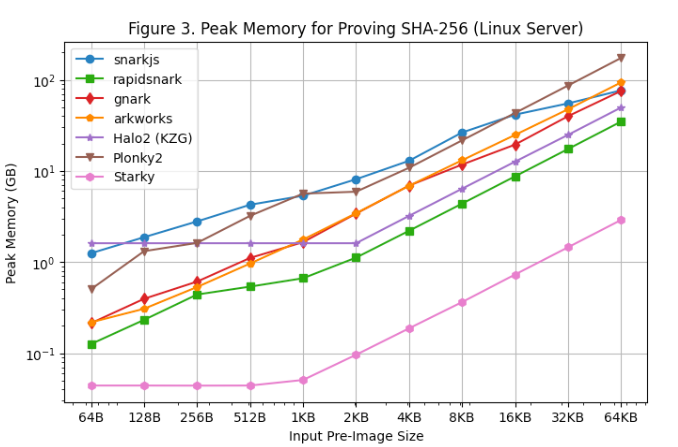
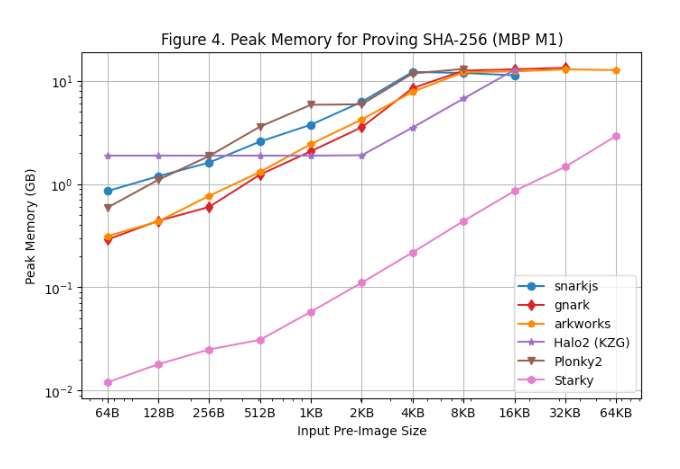
[图 3] 和 [图 4] 分別顯示了在Linux Server 和Macbook M1 Pro 上生成證明期間的內存使用峰值。根據這些性能測試結果可以得出以下觀察結果:
- 在所有SNARK 框架中,rapidsnark 是內存效率最高的。我們還看到,由於查找表的固定設置成本,當原像尺寸較小時,Halo2 使用更多內存,但當原像尺寸較大時,整體消耗的內存較少。
- Starky 的內存效率比SNARK 框架高10 倍以上。部分原因是它使用了更少的行。
- 應該注意的是,由於使用交換內存,原像尺寸變大,因此Macbook M1 Pro 上的內存使用量峰值保持相對平穩。
CPU 利用率
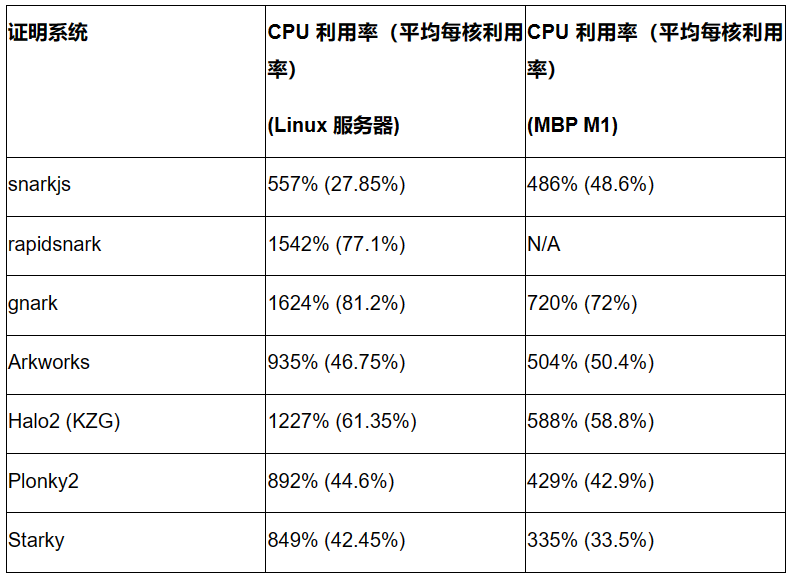
我們通過測量SHA-256 在4KB 原像輸入的證明生成期間的平均CPU 利用率來評估每個證明系統的並行化程度。下表顯示了Linux Server(20 核)和Macbook M1 Pro(10 核)上的平均CPU 利用率(括號中為每個內核的平均利用率) 。
主要觀察結果如下:
- Gnark 和rapidsnark 在Linux 服務器上表現出最高的CPU 利用率,表明它們能夠有效地使用多核且並行化生成證明。 Halo2 也展現了良好的並行化性能。
- 大多數框架在Linux 服務器上的CPU 利用率是在Macbook Pro M1 的2 倍,只有snarkjs 例外。
- 儘管最初預計基於FRI 的框架(Plonky2 和Starky)可能難以有效地使用多核,但它們在我們的性能測試中的表現並不比某些Groth16 或KZG 框架差。在具有更多內核(例如100 個內核)的機器上,CPU 利用率是否會有差異還有待觀察。
結論及未來研究
這篇文章全面比較了SHA-256 在各種zk-SNARK 和zk-STARK 開發框架上的性能測試結果。通過比較,我們深入了解了每種框架的效率和實用性,以期可以幫助需要為SHA-256 操作生成簡潔證明的開發者。
我們發現Groth16 框架(例如rapidsnark、gnark)在生成證明方面比Plonk 框架(例如Halo2、Plonky2)更快。 Plonkish 算術化中的查找表在使用較大的原像尺寸時顯著減少了SHA-256 的約束和證明時間。此外,gnark 和rapidsnark 展示了利用多核以並行化運作的出色能力。另一方面,Starky 的證明生成時間要短得多,但代價是證明大小要大得多。在內存效率方面,rapidsnark 和Starky 優於其他框架。
作為構建零知識證明評測平台「萬神殿Patheon」 的第一步,我們承認本次性能測試結果遠不足以成為最終我們希望構建的一個綜合測試平台。我們歡迎並樂於接受反饋和批評,並邀請所有人為這項倡議做出貢獻,以便開發者更容易、低門檻地使用零知識證明。我們也願意為個人獨立貢獻者提供資助,以支付大規模性能測試的計算資源成本。我們希望可以共同提高ZKP 的效率和實用性,更為廣泛地造福社區。
最後,我們要感謝Polygon Zero 團隊、Consensys 的gnark 團隊、Pado Labs 以及Delphinus Lab 團隊,感謝他們對性能測試結果的寶貴審查和反饋。

