
從chatGPT問世至今,AI就在以月為單位飛速進化著,其模型之多,迭代之快,讓很多人不不禁驚覺:人類似乎真的站在了AGI大門的邊緣。
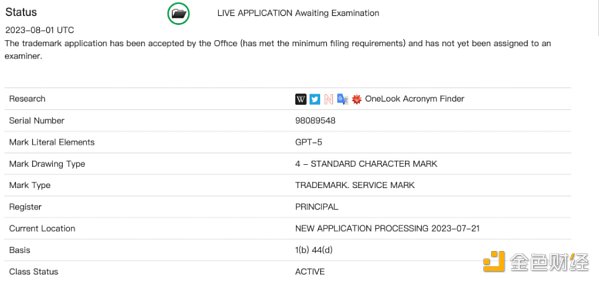
而最近,美國專利商標局 (USPTO) 披露的一份文件顯示:OpenAI於7月18日提交了「GPT-5」的商標申請。並且已經被接收。
USPTO 文件截圖
儘管在今年上半年,各個AI專家、學者已經多次聯合發表公開信,呼籲人們重視生成式AI 的潛在風險,而OpenAI當時也宣布短期內不會有訓練GPT-5的計劃。
然而,科技的誘惑,終究還是讓人類打破了禁忌的邊界。
在這次披露的申請書中,OpenAI提到,尚未發布的GPT-5將具備眾多GPT-4所沒有的能力,而且幾乎每一項都劍指AGI。

USPTO 文件截圖
那麼,這樣的改變,對AI和人類而言,又意味著什麼?
今天,本文就將嘗試從OpenAI的申請文件中披露的有限信息,對GPT-5可能的功能、變化,及所造成的影響,進行一番簡單的剖析。
01 通往AGI之路
在此次披露的文件中,OpenAI最先提到的一個變化,就是多模態功能的加強。
具體來說,GPT-5 的功能包括把文本或語音從一種語言翻譯成另一種語言、語音識別、生成文本和語音等。

雖然在現在的GPT-4中,用戶同樣可以實現不同語種間的翻譯,但既然翻譯功能在這裡被單獨挑出來,想必是重新優化過了。
那OpenAI為何會如此突出GPT-5的翻譯能力?
這或許是因為,GPT走向通用的前提之一,就是盡可能縮小不同語言使用大模型的成本差距。
此前,牛津大學的研究成果顯示,由於OpenAI 等服務所採用的服務器成本衡量,和計費的方式的不同,英語輸入和輸出的費用要比其他語言低得多。
其中簡體中文的費用大約是英語的兩倍,西班牙語是英語的1.5 倍,而緬甸的撣語則是英語的15 倍。

因為像中文這樣的語言有著不同、更複雜的結構,導致它們需要更高的詞元化率。
例如,根據OpenAI 的GPT3 分詞器,“你的愛意(your affection)” 的詞元,在英語中只需要兩個詞元,但在簡體中文中需要八個詞元。
這意味著,除了英語之外的其他語言,使用和訓練模型要貴得多。
而一旦翻越了“語言障礙”這道檻,無疑會直接地掃清橫亙在GPT面前的這條通用性障礙。
除此之外,文件中突出的語音識別功能,看似只是一個不起眼的改動,但從某種程度上說,這也是OpenAI對GPT-5在通往AGI的道路上鋪下的又一塊路磚。
眾所周知,在今後的大模型發展方向上,模型變得邊緣化、終端化,已經成了一個愈發明顯的趨勢。
自從今年7月,高通發布了能在手機上運行的10億參數大模型後,榮耀、蘋果等廠商,也相繼宣布要推出自身的“大模型”手機。

以手機為起點,將來的AI數據,將會越來越多地在攝像頭、傳感器、自動駕駛等終端側進行處理。
而在這樣的應用場景中,語音識別無疑更便捷、高效。
例如,AI語言模型可以讓駕駛員可以通過語音控制車輛行駛。將駕駛員的語音指令轉化為可執行的指令,例如啟動、停止、加速、剎車等操作。
而類似於SIri那樣存在於手機系統中的智能助手,也會優先考慮通過語音指令來進行控制。
由此可見,語音識別並非只是錦上添花,而是GPT-5進入終端側的“標配”,
而通過在這一個個終端設備的下沉,GPT-5也將由此獲得更多邊緣化的、非語言的數據結構。
畢竟,大模型發展至今,能汲取的文本數據,已經差不多了,要想在通往AGI的路上再上一個台階,這種“非文本”的數據,就顯得至關重要。
02 挑戰專家模型
除了上述特點外,OpenAI提交的文件中還提到:“GPT-5 可能還具備學習、分析、分類和回應數據的能力”。
從目前人工智能的發展趨勢來看,這很可能是指GPT-5具備了類似智能體的主動學習能力。
而這樣的能力,將會使GPT-5與以往只能被動地通過人類投餵數據,來學習新知識的模型相比,產生本質的區別。

具體來說,主動學習的能力,是指模型可以根據自身的目標和需求,自主地選擇、獲取和處理數據,而不是僅僅依賴於人類提供的數據。
這樣可以讓模型更有效地利用數據中的信息和知識,更靈活地適應不同的數據環境和任務場景,而不只是被動地接收和輸出數據。
而這樣的能力,在GPT-5面臨一些比較陌生、垂直的領域時,就顯得尤為重要。
一些特定的領域,比如醫學、法律、金融等,通常有著自己特定的術語、規則和知識體系,對於普通的語言模型來說,可能難以理解和處理。
如果GPT-5具備了主動學習的能力,它可以自動地從網絡上蒐集和更新這些領域的相關數據,分析和分類這些領域的基本概念、重要原理和最新動態,以及回應這些領域的常見問題、典型案例和實際應用。

如此,可以讓GPT-5更快地掌握這些領域的專業知識,更準確、高效地完成這些領域的相應任務。
而這一切,正是其邁向真正的通用大模型的關鍵。
因為如果GPT始終需要接入特定的“專家模型”,才能解決專業任務,那它就談不上真正的“通用”。
因為這樣會導致GPT對於不同領域和場景的智能能力存在差異和依賴,而且也會增加GPT與“專家模型”的溝通和協調成本,而不能保證在任何情況下都能實現高質量的服務。
此前,外媒Semianalysis 就對今年3月發布的GPT-4進行了揭秘,曝光了OpenAI採用混合專家模型來構建GPT-4。
根據爆料,GPT-4 使用了16個混合專家模型(mixture of experts),每個有1110億個參數,每次前向傳遞路由經過兩個專家模型。
然而,更多的專家模型意味著更難泛化,也更難實現收斂。

這是因為每個專家模型都有自己的參數和策略,往往很難協調一致,進而使得GPT難以平衡和“顧全大局”。
而在具備了主動學習的能力後,GPT-5將有可能利用多模態的理解和推理能力,以及知識圖譜和數據庫,來分析和理解獲取到的數據,並通過聚類算法和分類器,對相關數據進行關聯和歸納。
如此,GPT-5就能根據不同的數據環境和任務場景,有效地利用數據中的信息和知識。
03 取代更多工作
如前所述,在掃清了語言障礙,並以便捷的語音識別功能進入終端側後,GPT-5將通過持續的主動學習能力,不斷汲取不同場景、領域和模態下的知識,進而向著AGI的道路高速前行。
可以預見的是,當具備了這樣強大“通用性”的GPT-5,開始向各領域擴散後,除了少數具有數據壁壘的行業(如醫療)外,大部分垂直領域的大模型,都將會逐漸黯然失色。
因為說到底,相當一部分專家或垂直大模型,本質上是某些企業算力、數據不足,無法高攀“通用大模型”,而不得不退而求其次的產物(這在國內尤為明顯)。
倘若一個通用大模型,憑藉強大的學習能力,就能夠精通大部分行業,那誰又會願意繁瑣地在不同的模型之間切換,並為不同的模型承擔多份訓練、使用成本呢?
從這點上來說,專家模型逐漸被通用模型取代,是人類在通往AGI道路上一個不可避免的歷史過程。
而與此相伴的另一個現象,則是更多細分的、瑣碎的工作被取代。

因為在有了更強大的通用大模型後,人們將會發現,其實很多崗位的工作內容,是可以被合併、被統合的。
產品經理和數據分析師就是一個可能的例子。
例如,在一個新產品開發的項目中,GPT-5可以根據給定的產品概念或需求,從網絡上搜索相關的市場調研、競品分析、用戶畫像等數據,並下載到自己的內存中。
之後,它會通過自己的多模態的理解和邏輯推理能力,以及知識圖譜和數據庫,來分析和理解獲取到的數據。

在得到了相應的數據,並將其進行分類和組織後,GPT-5就會通過語言理解能力,從對話系統的反饋中學習相關的營銷策略、用戶反饋等信息,並將其與給定的產品概念或需求進行比較和評估。
如此一來,產品經理和數據分析師這兩個崗位,就被高效地“合併”了。
而在通往AGI的未盡之路上,這樣被合併和取代的崗位,還有無數種。
因此,一個通用性更強的GPT-5,對人類而言,既是生產力進步的福音,但同時也是行業大地震的前奏。
到了那時,許多尚不具備通用大模型能力,又缺乏行業壁壘的企業,將會如沙子堆起的城堡一樣,脆弱地倒下。
而更多普通的個體,面對不斷被取代的崗位,將會更深刻地感受到時代的不確定性……