

2012年12月初的某天,一場秘密競拍正在美國滑雪勝地太浩湖(Lake Tahoe)的一家賭場飯店進行。
太浩湖位於加州和內華達州交界處,是北美最大的高山湖泊,擁有藍寶石般的湖面和頂級雪道,《教父2》曾在這裡取景,馬克吐溫曾在此地流連忘返,而由於離舊金山灣區只有200多英里,這裡常被稱為“矽谷後花園”,扎克伯格和拉里·埃里森等大佬也在此圈地佔山,興建豪宅。
秘密競標的對象,是一家剛成立1個月、僅有3名員工的公司-DNNresearch,創立者是多倫多大學教授傑夫·辛頓(Geoffrey Hinton)和他兩名學生。
這家公司沒有任何有形的產品或資產,但追求者的身分暗示出了它的分量——四位買家分別是Google、微軟、DeepMind和百度。
舉行秘密競拍的Harrah’s酒店,太浩湖,2012年
65歲的辛頓蒼老,瘦削,飽受腰椎間盤的疼痛,他坐在酒店703房間的地板上為競拍設置規則——起價1200萬美元,抬價單位至少100萬美元。
幾個小時後,競標者就把價格推到了4400萬美元,辛頓有些頭暈,“感覺我們像是在拍電影”,於是果斷喊停,並決定把公司賣給最後的喊價者——Google 。
有趣的是,這場4,400萬美元競標的源頭之一,就是來自於6個月前的Google。
2012年6月,Google研究部門Google Brain公開了The Cat Neurons計畫(即「Google貓」)的研究成果。這個計畫簡單說就是用演算法在YouTube的影片裡辨識貓,它由從史丹佛跳槽來Google的吳恩達發起,拉上了Google傳奇人物Jeff Dean入夥,還從Google創始人Larry Page那裡要到了大筆的預算。
谷歌貓計畫搭建了一個神經網絡,從YouTube上下載了大量的視頻,不做標記,讓模型自己觀察和學習貓的特徵,然後動用了遍布Google各個數據中心的16000個CPU來進行訓練(內部以過於複雜且成本高為由拒絕使用GPU),最終達到74.8%的辨識準確率。這數字震驚業界。
吳恩達在「谷歌貓」計畫臨近結束前激流勇退,投身自己的網路教育項目,臨走前他向公司推薦了辛頓來接替他的工作。面對邀請,辛頓表示自己不會離開大學,只願意去Google「待一個夏天」。由於Google招募規則的特殊性,當時64歲的辛頓成為了Google史上最年長的暑期實習生。
辛頓從80年代開始就戰斗在人工智慧的最前線,作為教授更是桃李滿門(包括吳恩達),是深度學習領域的宗師級人物。因此,當他了解了“谷歌貓”項目的技術細節後,他馬上就看到了項目成功背後的隱藏缺陷:“他們運行了錯誤的神經網絡,並使用了錯誤的計算能力。”
同樣的任務,辛頓認為自己可以做的更好。於是在短暫的「實習期」結束後,他馬上投入行動。
辛頓找來了自己的兩個學生——Ilya Sutskever和Alex Krizhevsky,兩人都是出生於蘇聯的猶太人,前者極具數學天賦,後者擅長工程實現,三人密切配合後創建了一個新神經網絡,然後馬上參加了ImageNet圖像識別比賽(ILSVRC),最後以驚人的84%識別準確率奪得冠軍。
2012年10月,辛頓團隊在佛羅倫斯舉行的電腦視覺會議上介紹了冠軍演算法AlexNet,相較於Google貓咪用了16,000顆CPU,AlexNet只用了4顆英偉達GPU,學術界和產業界徹底轟動,AlexNet的論文成為電腦科學史上最有影響力的論文之一,目前被引次數已經超過12萬,而Google貓則被迅速遺忘。

DNNresearch公司三人組
曾拿過第一屆ImageNet大賽冠軍的餘凱讀完論文後異常興奮,「像觸電了一樣」。餘凱是一位出生於江西的深度學習專家,剛從NEC跳去百度,他馬上給辛頓寫郵件,表達了合作的想法,辛頓欣然同意,並索性把自己和兩名學生打包成一家公司,邀請買家競標,於是便有了開頭的那一幕。
拍賣落槌後,一場更大的競賽展開了:Google乘勝追擊,2014年又把DeepMind收入囊中,「天下英雄盡入彀中」;而DeepMind則在2016年推出了AlphaGo,震驚全球;輸給Google的百度則下定決心押注AI,十年投入千億,餘凱後來幫百度請來了吳恩達,他自己則在幾年後離職創辦了地平線。
微軟表面上看慢了一拍,但最終卻贏下了最大的戰利品——OpenAI,後者的創始人包括辛頓兩個學生之一的Ilya Sutskever。而辛頓自己則一直在Google待到2023年,期間榮獲ACM圖靈獎。當然,跟Google的4400萬美元比(辛頓分得40%),圖靈獎的100萬美元獎金就顯得零用錢了。
從6月的Google貓,到10月的AlexNet論文,再到12月的太浩湖競拍,差不多6個月的時間裡,AI浪潮的伏筆幾乎被全部埋下——深度學習的繁榮、GPU和英偉達的崛起、AlphaGo的稱霸、Transformer的誕生、ChatGPT的橫空出世……矽基盛世的宏大樂章奏響了第一個音符。
2012年從6月到12月的180天,碳基人類的命運被永遠改變了──只有極少人意識到了這一點。
液體貓
在這些極少數人中,史丹佛大學教授李飛飛是其中之一。
2012年,當辛頓參加ImageNet比賽結果出爐時,剛生完孩子的李飛飛還在休產假,但辛頓團隊的錯誤率讓她意識到歷史正在被改寫。身為ImageNet挑戰賽的創辦人,她買了當天最後一班飛機飛往佛羅倫斯,親自為辛頓團隊頒獎[2]。
李飛飛出生於北京,成都長大,16歲時隨父母移民美國,一邊在洗衣店幫忙,一邊讀完普林斯頓。 2009年李飛飛進入史丹佛擔任助理教授,研究方向是電腦視覺與機器學習,這個學科的目標是讓電腦能夠像人一樣,自己理解圖片和影像的意義。
例如,當相機拍下一隻貓時,它只是透過感光元件把光線轉化成了像素,並不知道鏡頭裡的東西是貓還是狗。如果把照相機比做人類的眼睛,電腦視覺解決的問題就是給照相機裝上人的大腦。
傳統的方式是將現實世界中的事物抽象化為數學模型,例如將貓的特徵抽象化為簡單的幾何圖形,就能大幅降低機器辨識的難度。
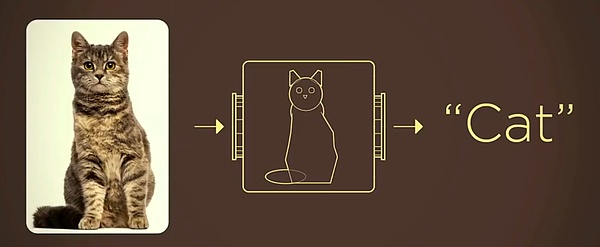
圖片來源:李飛飛的TED演講
但這種想法有非常大的局限性,因為貓很有可能是這樣的:

為了讓電腦能夠識別“液體貓”,傑夫·辛頓、楊立昆(Yann LeCun)等一大批深度學習先驅從80年代就開始了探索。但總是會撞到算力或演算法的瓶頸——好的演算法缺少足夠的算力驅動,算力需求小的演算法難以滿足辨識精度,無法產業化。
如果解決不了「液體貓」的問題,深度學習的性感就只能停留在理論層面,自動駕駛、醫療影像、精準廣告推播這些產業化場景就只是空中樓閣。
簡單來說,深度學習的發展需要演算法、算力、資料三駕馬車來拉動,演算法決定了電腦用什麼方式辨識事物;但演算法又需要夠大的算力來驅動;同時,演算法的提升又需要大規模高品質的數據;三者相輔相成,缺一不可。
2000年後,儘管算力瓶頸伴隨晶片處理能力的突飛猛進逐步消除,但主流學界對深度學習路線仍舊興趣寡然。李飛飛意識到,瓶頸可能不是演算法本身的精確度,而是缺乏高品質、大規模的資料集。
李飛飛的啟發來自三歲孩子認識這個世界的方式──以貓為例,孩子會在大人的教導下一次又一次遇見貓,逐漸掌握貓的意義。如果把孩子的眼睛當作相機,眼球轉動一次等於按一次快門,那麼,一個三歲的孩子就已經拍了上億張照片。
把這個方法套在計算機上,如果給計算機不停的看包含貓和其他動物的圖片,同時在每張圖片背後寫下正確答案。計算機每看一次圖片,就和背面的答案核對一次。那麼只要次數夠多,計算機就有可能像小孩一樣掌握貓的意思。
唯一需要解決的問題就是:上哪找這麼多寫好答案的圖片?

李飛飛在2016年來到中國,宣布GoogleAI中國中心成立
這就是ImageNet誕生的機會。當時,即便是最大規模的資料集PASCAL,也只有四個類別總共1578張圖片,而李飛飛的目標是創建一個包含幾百個類別總共上千萬張的資料集。現在聽起來似乎不難,但要知道那是2006年,全球最受歡迎的手機還是諾基亞5300。
依靠亞馬遜眾包平台,李飛飛團隊解決了人工標註的龐大工作量。 2009年,包含320萬張圖片的ImageNet資料集誕生。有了圖片資料集,就可以在此基礎上訓練演算法,讓電腦提升辨識能力。但相較於三歲孩子的上億張照片,320萬的規模還是太少了。
為了讓資料集不斷擴充,李飛飛決定效仿業界流行的做法,舉辦圖片辨識競賽,參賽者自備演算法辨識資料集中的圖片,準確率最高者獲勝。但深度學習路線在當時並不是主流,ImageNet一開始只能「掛靠」在歐洲知名賽事PASCAL下面,才能勉強湊夠參賽人數。
到了2012年,ImageNet的圖片數量擴大到了1000個類別總共1500萬張,李飛飛用6年時間補足了數據這塊短板。不過,ILSVRC的最佳成績錯誤率也有25%,在演算法和算力上,依然沒有表現出足夠的說服力。
這時,辛頓老師帶著AlexNet和兩塊GTX580顯示卡登場了。
卷積
辛頓團隊的冠軍演算法AlexNet,採用了一種名叫卷積神經網路(Convolutional Neural Networks,簡稱CNN)的演算法。 「神經網路」在人工智慧領域是個極為高頻的詞彙,也是機器學習的一個分支,其名稱和結構都取材自人腦的運作方式。
人類辨識物體的過程是瞳孔先攝取像素,大腦皮質透過邊緣和方位做初步處理,然後大腦透過不斷的抽象來判定。因此,人腦可以根據一些特徵就能判別出物體。
例如不用展示整張臉,大部分人都能認出下圖的人是誰:

神經網路其實就是模擬人腦的辨識機制,理論上人腦能實現的智慧型電腦也能實現。相較SVM、決策樹、隨機森林等方法,只有模擬人腦,才能處理類似「液體貓」和「半川普」這種非結構化資料。
但問題是,人腦約有1000億個神經元,神經元之間的節點(也就是突觸)更是多達萬億,組成了一個無比複雜的網路。作為對比,用了16,000個CPU組成的“Google貓”,內部共有10億個節點,而這已經是當時最複雜的電腦系統了。
這也是為什麼連「人工智慧之父」Marvin Minsky都不看好這條路線,在2007年出版新書《The Emotion Machine》時,Minsky依然表達了對神經網路的悲觀。為了改變主流機器學習界對人工神經網路的長期的負面態度,辛頓乾脆將其改名為深度學習(Deep Learning)。
2006年,辛頓在Science上發表了一篇論文,提出了「深度信念神經網路(DBNN)」的概念,給出了一種多層深度神經網路的訓練方法,被認為是深度學習的重大突破。但辛頓的方法需要消耗大量的算力和數據,實際應用難以實現。
深度學習需要不停的給演算法餵數據,當時的數據集規模都太小了,直到ImageNet出現。
ImageNet的前兩屆比賽裡,參賽團隊使用了其他的機器學習路線,結果都相當平庸。而辛頓團隊在2012年採用的捲積神經網路AlexNet,改良自另一位深度學習先驅楊立昆(Yann LeCun),在1998年提出的LeNet讓演算法可以擷取影像的關鍵特徵,例如川普的金髮。
同時,卷積核會在輸入影像上滑動,所以無論被偵測物體在哪個位置,都能被偵測到相同的特徵,都大大減少了運算量。
AlexNet在經典的捲積神經網路結構基礎上,拋棄了先前的逐層無監督方法,對輸入值進行有監督學習,大大提高了準確率。
例如下圖中右下角的圖片,AlexNet其實並沒有辨識出正確答案(馬達加斯加貓),但它列出的都是和馬達加斯加貓一樣會爬樹的小型哺乳動物,這意味著演算法不僅可以辨識物件本身,也可以根據其他物體進行推測[5]。

圖片來源:AlexNet論文
而產業界感到振奮的是,AlexNet有6000萬個參數和65萬個神經元,完整訓練ImageNet資料集至少需要262千萬億次浮點運算。但辛頓團隊在一個星期的訓練過程中,只用了兩塊英偉達GTX 580顯示卡。
GPU
辛頓團隊拿到冠軍後,最尷尬的顯然是Google。
據說Google在內部也做了ImageNet資料集的測試,但辨識精度遠遠落後於辛頓團隊。考慮到Google擁有業界無法企及的硬體資源,以及搜尋和YouTube的龐大資料規模,Google Brain更是領導欽點特事特辦,其結果顯然不具備足夠的說服力。
如果沒有這種巨大的反差,深度學習可能也不會在短時間內震撼業界,得到認可和普及。產業界感到振奮的原因在於辛頓團隊只用了四塊GPU,就能達到這麼好的效果,那麼算力就不再是瓶頸。
演算法在訓練時,會對神經網路每層的函數和參數進行分層運算,得到輸出結果,而GPU恰好有非常強的平行運算能力。吳恩達在2009年的一篇論文中其實證明了這一點,但在和Jeff Dean運行「谷歌貓」時,他們還是用了CPU。後來Jeff Dean特別訂購了200萬美元的設備,依然不包括GPU[6]。
辛頓是極少數很早就意識到GPU之於深度學習巨大價值的人,然而在AlexNet刷榜之前,高科技公司普遍對GPU態度不明。
2009年,辛頓曾受邀到微軟當一個語音辨識專案的短期技術顧問,他建議專案負責人鄧力購買最頂級的英偉達GPU,還要搭配對應的伺服器。這個想法得到了鄧力的支持,但鄧力的上司Alex Acero認為這純屬亂花錢[6],“GPU是用來玩遊戲的,而不是用來做人工智慧研究的。”

鄧力
有趣的是,Alex Acero後來跳槽去了蘋果,負責蘋果的語音辨識軟體Siri。
而微軟對GPU的不置可否顯然讓辛頓有些火大,他後來在一封郵件裡建議鄧力購買一套設備,而自己則會買三套,並且陰陽怪氣的說[6]:畢竟我們是一所財力雄厚的加拿大大學,不是一家資金緊張的軟體銷售商。
但在2012年ImageNet挑戰賽結束後,所有人工智慧學者和科技公司都對GPU來了個180度大轉彎。 2014年,Google的GoogLeNet以93%的辨識準確率奪冠,採用的正是英偉達GPU,這一年,所有參賽團隊GPU的使用數量飆升到了110塊。
這屆挑戰賽之所以被視為“大爆炸時刻”,在於深度學習的三駕馬車——算法、算力、數據上的短板都被補足,產業化只剩下了時間問題。
演算法層面,辛頓團隊發表的關於AlexNet的論文,成為電腦科學領域被引用次數最多的論文之一。原本百家爭鳴的技術路線成了深度學習一家獨大,幾乎所有的電腦視覺研究都轉向了神經網路。
算力層面,GPU超強平行運算能力與深度學習的適應性迅速被業界認可,六年前開始佈局CUDA的英偉達成為了最大的贏家。
資料層面,ImageNet成為影像處理演算法的試金石,有了高品質的資料集,演算法辨識精度日行千里。 2017年最後一屆挑戰賽,冠軍演算法的辨識準確率達到97.3%,超過了人類。
2012年10月底,辛頓的學生Alex Krizhevsky在義大利佛羅倫斯的電腦視覺會議上公佈了論文。然後,全世界的高科技公司開始不計成本地兩件事:一是買光英偉達的顯卡,二是挖光大學裡的AI研究員。
太浩湖的4400萬美元,給全球的深度學習大神做了一次重新定價。
奪旗
從公開可查的資訊看,當時還在百度的餘凱的確是第一個來挖辛頓的人。
當時,餘凱在百度擔任百度多媒體部門的負責人,也就是百度深度學習研究院(IDL)的前身。在收到餘凱的郵件後,辛頓很快就回覆說同意合作,順帶提出了希望百度提供一些經費的願望。餘凱問具體數字,辛頓表示100萬美元就夠——這個數字低到令人難以置信,只能僱用兩個P8。
餘凱向李彥宏請示,後者爽快地答應。餘凱回覆沒問題後,辛頓可能感受到了產業界的飢渴,就詢問餘凱是否介意自己問問其他家,例如Google。餘凱後來在回憶道[6]:
“我當時有點後悔,猜我可能回答得太快了,讓辛頓意識到了巨大的機會。但是,我也只能大度地說不介意。”
最終百度跟辛頓團隊失之交臂。但對於這個結果,餘凱並非沒有心理準備。因為一方面辛頓有嚴重的腰椎間盤健康問題,不能開車,也不能坐飛機,很難承受跨越太平洋的中國之旅;另一方面,辛頓有太多的學生和朋友在谷歌工作了,雙方淵源太深,其他三家本質上就是在陪標。
如果說AlexNet的影響還集中在學術圈的話,那麼太浩湖的秘密拍賣則徹底震驚了產業界——因為谷歌在全球科技公司的眼皮子底下,花了4400萬美元買了一家成立不到一個月、沒有產品、沒有收入,只有三個員工和幾篇論文的公司。
最受刺激的顯然是百度,雖然在拍賣上折戟,但百度管理層親眼目睹了Google如何不惜代價投資深度學習,促使百度下定決心投入,並在2013年1月的年會上宣布成立深度學習研究院IDL。 2014年5月,百度請來了「Google貓」計畫的關鍵人物吳恩達,2017年1月,又請來了離開微軟的陸奇。
而Google在拿下辛頓團隊後再接再厲,在2014年以6億美元買下了當年的競標對手DeepMind。
當時,馬斯克向Google創辦人Larry Page推薦了自己投資的DeepMind,為了能帶上辛頓一起去倫敦驗驗成色,Google團隊還專門包了架私人飛機,並且改造了座椅,解決辛頓不能坐飛機的問題[6]。

「英國選手」DeepMind在圍棋比賽中擊敗了李世石,2016年
和Google爭奪DeepMind的是Facebook。當DeepMind花落Google後,祖克柏轉而挖了「深度學習三巨頭」之一的楊立昆。為了將楊立昆納入麾下,祖克柏答應了他許多苛刻要求,例如AI實驗室設立在紐約,實驗室與產品團隊完全劃清界限,允許楊立昆繼續在紐約大學任職等等。
2012年ImageNet挑戰賽後,人工智慧領域面臨非常嚴重的「人才供需錯配」問題:
由於推薦演算法、影像辨識、自動駕駛這些產業化空間被迅速打開,人才需求量激增。但由於長期不被看好,深度學習的研究者是個很小的圈子,頂尖學者更是兩隻手數得過來,供給嚴重不足。
這種情況下,如飢似渴的科技公司只能購買「人才期貨」:把教授挖過來,然後等他們把自己的學生也帶進來。
楊立昆加入Facebook後,先後有六名學生跟隨他入職。準備在造車上躍躍欲試的蘋果挖來了辛頓的學生Ruslan Salakhutdinov,擔任蘋果首任AI總監。就連對沖基金Citadel也加入了搶人大戰,挖走了當年和辛頓搞語音辨識、後來還代表微軟參與秘密競標的鄧力。



此後的歷史我們再清楚不過:人臉辨識、機器翻譯、自動駕駛等產業化場景日行千里,GPU訂單雪花一般飄向聖克拉拉的英偉達總部,人工智慧的理論大廈也在日復一日的澆築。
2017年,Google在論文《Attention is all you need》裡提出Transformer模型,開啟瞭如今的大模型時代。幾年後,ChatGPT橫空出世。
而這一切的誕生,都可以追溯到2012年的ImageNet挑戰賽。
那麼,推動2012年「大爆炸時刻」誕生的歷史進程,又是在哪一年顯現的呢?
答案是2006年。
偉大
在2006年之前,深度學習的現狀可以藉用開爾文男爵的那句名言來概括:深度學習的大廈已經基本建成了,只不過在陽光燦爛的天空下,漂浮著三朵小烏雲。
這三朵小烏雲就是演算法、算力和數據。
如前文所說,由於模擬了人腦的機制,深度學習是理論上非常完美的方案。但問題在於,無論是它需要吞噬的數據,還是需要消耗的算力,在當時都是一個科幻級別的規模,科幻到學術界對深度學習的主流看法是:腦子正常的學者不會研究神經網絡。
但2006年發生的三件事改變了這一點:
辛頓和學生Salakhutdinov(就是後來去蘋果的那位)在Science上發表了論文Reducing the dimensionality of data with neural networks,第一次提出了有效解決梯度消失問題的解決方案,讓演算法層面邁出了一大步。

Salakhutdinov(左一)與辛頓(中),2016年
史丹佛大學的李飛飛意識到,如果資料規模難以還原現實世界的原貌,那麼再好的演算法也很難透過訓練達到「模擬人腦」的效果。於是,她開始著手搭建ImageNet資料集。
英偉達發表Tesla架構的新款GPU,並隨之推出CUDA平台,開發者利用GPU訓練深度神經網路的難度大幅降低,望而生畏算力門檻被砍掉了一大截。
這三件事的發生吹散了深度學習上空的三朵烏雲,並在2012年的ImageNet挑戰賽上交匯,徹底改寫了高科技產業乃至整個人類社會的命運。
但在2006年,無論是傑夫辛頓、李飛飛、黃仁勳,還是其他推動深度學習發展的人,顯然都無法預料人工智慧在此後的繁榮,更不用說他們所扮演的角色了。

Hinton和Salakhutdinov的論文
時至今日,AI為核心驅動的第四次工業革命又開啟了,人工智慧的演進速度只會越來越快。如果說我們能得到多少啟發,也許不外乎以下三點:
1.產業的厚度決定創新的高度。
ChatGPT橫空出世時,「為什麼又是美國」的聲音此起彼伏。但如果把時間拉長,會發現從電晶體、積體電路,到Unix、x86架構,再到如今的機器學習,美國學界和產業界幾乎都是領跑者的角色。
這是因為,雖然關於美國「產業空洞化」的討論不絕於耳,但以軟體為核心的電腦科學這門產業,不僅從未「外流」到其他經濟體,反而優勢越來越大。至今70多位ACM圖靈獎的得主,幾乎都是美國人。
吳恩達之所以選擇Google合作「Google貓」項目,很大程度上是因為只有Google擁有演算法訓練所需的數據和算力,而這又建立在Google強大的獲利能力的基礎上。這就是產業厚度帶來的優勢──人才、投資、創新能力都會向產業的高地靠攏。
中國在自身的優勢產業裡,也體現出這種「厚度優勢」。目前最典型的就是新能源車,一邊是歐洲車企包機來中國車展拜師新勢力,一邊是日本車企高層頻繁跳槽到比亞迪-圖什麼?顯然不是只圖能在深圳交社保。
2.越是前沿的技術領域,人才的重要性就越大。
Google之所以願意花4400萬美元買下辛頓的公司,是因為在深度學習這樣的前沿技術領域,一個頂級學者的作用,往往大過一萬個計算機視覺專業的應屆生。假如當時競拍成功的是百度或微軟,人工智慧的發展脈絡可能都會被改寫。
這種「為了你買下整個公司」的行為,其實非常常見。蘋果自研晶片的關鍵階段,順手買了PASemi的小公司,就是為了把晶片架構大神Jim Keller挖到手——蘋果的A4、AMD的Zen、特斯拉的FSD晶片,都得到了Jim Keller的技術扶貧。
這也是產業競爭力帶來的最大優勢──對人才的吸引力。
「深度學習三巨頭」沒有一個是美國人,AlexNet這個名字來自辛頓的學生Alex Krizhevsky,他出生在蘇聯治下的烏克蘭,在以色列長大,來加拿大讀書。更不用說如今仍活躍在美國高科技公司的眾多華人面孔。
3.創新的難度在於,如何面對不確定性。
除了「人工智慧之父」Marvin Minsky反對深度學習之外,另一個知名深度學習反對者是加州大學柏克萊分校的Jitendra Malik,辛頓和吳恩達都被他冷嘲熱諷過。李飛飛在搭建ImageNet時也曾諮詢過Malik,後者給她的建議是:Do something more useful(做點更有用的事)。

李飛飛Ted演講
正是這些產業先驅的不看好,導致深度學習經歷了數十年的萬馬齊喑。即便到了2006年辛頓撕開了一束曙光,三巨頭的另一位楊立昆還在反覆向學術界證明「深度學習也有研究價值」。
楊立昆從80年代就開始研究神經網絡,在貝爾實驗室期間,楊立昆就和同事設計了一種名叫ANNA的晶片,試圖解決算力問題。後來AT&T由於經營壓力要求研究部門“賦能業務”,楊立昆的回答是“我就是要研究電腦視覺,有本事你解僱我”。最終求錘得錘,喜提N+1[6]。
任何尖端科技領域的研究者都必須面對一個問題──如果這個東西做不出來怎麼辦?
從1972年進入愛丁堡大學算起,辛頓在深度學習的前線已經鏖戰了50年。 2012年ImageNet挑戰賽舉辦時,他已經65歲了。很難想像他在漫長的時間裡面對學術界的種種質疑,需要消解多少自我懷疑與否定。
如今我們知道,2006年的辛頓已經堅持到了黎明前最後的黑暗,但他自己也許並不知道這一點,更不用說整個學術界和產業界。就像2007年iPhone發佈時,大多數人的反應可能和當時微軟CEO鮑爾默是一樣的:
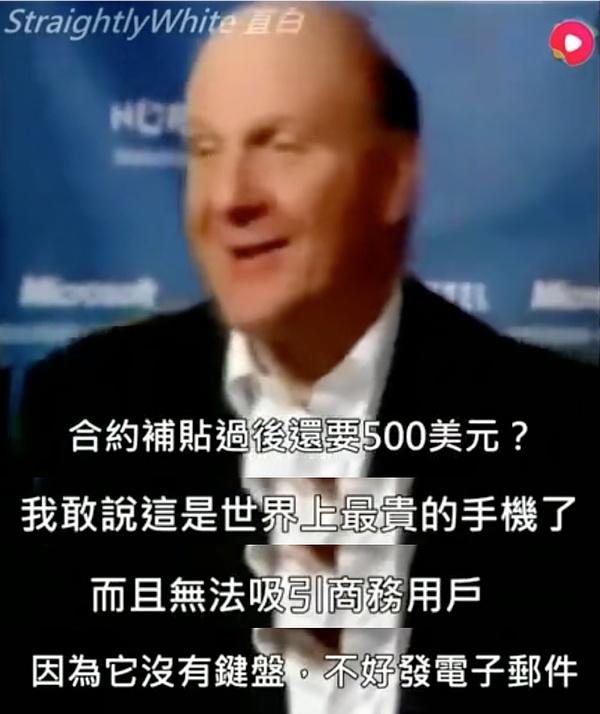
目前,iPhone依然是世界上最貴的手機,而且沒有鍵盤
推動歷史的人,往往猜不到自己在歷史進程中的座標。
偉大之所以為偉大,不是因為其橫空出世時的驚艷,而是因為它要在無邊黑暗中,忍受漫長的籍籍無名與不被理解。直到多年之後,人們才能順著這些標尺,感嘆那時群星璀璨,天才輩出。
在一個又一個科學研究的領域裡,無數的學者終其一生都不曾窺見希望的微光。因而從某個角度來看,辛頓和其他深度學習推動者是幸運的,他們創造了偉大,間接推動了產業界一個又一個成功。
資本市場會為成功定一個公允的價格,歷史則記錄那些創造偉大的孤獨和汗水。
參考資料
[1] 16,000台電腦一起找貓,紐約時報
[2] Fei-Fei Li’s Quest to Make AI Better for Humanity,Wired
[3] 李飛飛的TED演講
[4] 21秒看盡ImageNet屠榜模型,60+模型架構同台獻藝,機器之心
[5] 卷積神經網路的「封神之路」:一切始於AlexNet,新智元
[6] 深度學習革命,凱德‧梅茨
[7] To Find AI Engineers, Google and Facebook Hire Their Professors,The Information
[8] 深度學習三十年創新路,朱瓏
[9] ImageNet這八年:李飛飛和她改變的AI世界,量子位
[10] DEEP LEARNING: PREVIOUS AND PRESENT APPLICATIONS,Ramiro Vargas
[11] Review of deep learning: concepts, CNN architectures, challenges, applications, future directions,Laith Alzubaidi等
[12] Literature Review of Deep Learning Research Areas,Mutlu Yapıcı等
[13] ChatGPT背後真正的英雄:OpenAI首席科學家Ilya Sutskever的信仰之躍,新智元
[14] 10 years later, deep learning ‘revolution’ rages on, say AI pioneers Hinton, LeCun and Li,Venturebeat
[15] From not working to neural networking,經濟學人
[16] Huge “foundation models” are turbo-charging AI progress,經濟學人
[17] 2012: A Breakthrough Year for Deep Learning,Bryan House
[18] 深度學習:人工智慧的“神奇魔杖”,安信證券
[19] 深度學習演算法發展:從多元到統一,國金證券