
作者:Justin McAfee,1kx研究分析師;翻譯:金色財經xiaozou
通過zkSNARKs證明機器學習(ML)模型推理將成為這個十年智能合約發展最重要的進步之一。這一發展開闢了一個令人興奮的廣闊設計空間,允許應用程序和基礎設施發展成更複雜智能的系統。
通過添加機器學習功能,智能合約可以變得更加自主和動態,允許它們基於實時鏈上數據做出決策,而不僅僅囿於靜態規則。智能合約將更加靈活,可適應各種場景,包括那些合約初建時可能沒有預料到的場景。簡而言之,機器學習功能使我們置於鏈上的任何智能合約更加自動化、準確、高效和靈活。
從很多方面來看,鑑於機器學習在web3之外的大多數應用程序中的突出地位,智能合約沒有使用嵌入式ML模型著實令人驚訝。之所以不使用ML,主要是因為鏈上運行這些模型的計算成本太高。例如,FastBERT是一種計算優化的語言模型,使用約1800 MFLOPS(百萬浮點運算),直接在EVM上運行是行不通的。
在考慮鏈上ML模型的應用時,重點關注的是推理階段:應用模型對現實世界的數據進行預測。為了擁有ML規模的智能合約,合約必須能夠ingest(攝取)這類預測數據,但正如前面提到的,直接在EVM上運行ML模型是不可行的。 zkSNARK給我們提供了一個解決方案:任何人都可以在鏈下運行一個模型,並生成一個簡潔且可驗證的證明,證明預期模型確實產生了特定的結果。這個證明可以在鏈上發布,並被智能合約攝取,讓合約更加智能。
本文,我們將:
· 研究鏈上ML的潛在應用和用例;
· 探索zkML相關的新興項目和基礎設施建設;
· 討論現有實現面臨的一些挑戰,以及zkML的未來。
1、快速了解ML
機器學習(ML)是人工智能(AI)下面的一個領域,專注於開發算法和統計模型,使計算機能夠基於數據學習並做出預測或決策。 ML模型通常有三個主要組成部分:
· 訓練數據:即一組輸入數據,用於訓練機器學習算法進行預測或對新數據分類。訓練數據可以有多種形式,例如圖像、文本、音頻、數字數據或以上這些數據的組合。
· 模型架構:即某個機器學習模型的整體結構或設計。它定義了層的類型和數量、激活函數以及節點或神經元之間的連接。架構的選擇取決於具體問題和所使用的數據。
· 模型參數:即模型在訓練過程中學習的值或權重,以進行預測。這些值經過優化算法迭代調整,以最小化預測結果與實際結果之間的誤差。
模型的生成和部署分為兩個階段:
· 訓練階段:在訓練階段,模型暴露於標註數據集,並調整其參數以最小化預測結果與實際結果之間的誤差。訓練過程通常涉及若干迭代或epoch,模型的準確性會在單獨的驗證集上進行評估。
· 推理階段:推理階段是指使用經過訓練的機器學習模型對新的、未見過的數據進行預測。該模型接收輸入數據,並應用學習到的參數來生成輸出數據,例如分類或回歸預測。
zkML目前主要關注ML模型的推理階段,而不是訓練階段,這主要是礙於驗證在線訓練的計算複雜性。 zkML對驗證推理的關注並非是限制因素:我們期望從推理階段中可以產生出一些非常有趣的用例和應用程序。
2、驗證推理場景
驗證推理有四種可能的場景:
· 私有輸入,公共模型。模型消費者(MC)可能想對其輸入保密,不希望模型提供者(MP)知道。例如,MC可能希望在不披露個人財務信息的情況下向貸款人證明信用評分模型的結果。這可以通過使用預承諾方案並在本地運行模型來實現。
· 公共輸入,私有模型。 ML-as-a-Service(ML即服務)的一個常見問題是,MP可能希望隱藏他們的參數或權重以保護自己的IP,而MC希望驗證生成的推論確實來自於對抗設置中的指定模型。可以這樣考慮:MP在向MC提供推論時,有動機運行更輕型的模型以節省成本。使用鏈上模型權重承諾,MC可以隨時審計私有模型。
· 私有輸入,私有模型。當用於推理的數據高度敏感或高度機密,並且模型隱藏自身以保護IP時,就會出現這種情況。舉個關於這方面的例子:使用私有患者信息審計醫療保健模型。零知識證明(ZK)的複合技術或多方計算(MPC)的使用或FHE(全同態加密)的變體可用於服務於此場景。
· 公共輸入,公共模型。當模型的各方面都可以公開時,zkML將服務於一個不同用例:壓縮並驗證鏈下計算,以適應鏈上環境。對於較大的模型,驗證推理的簡潔的ZK證明比重新運行模型本身更具成本效益。
3、應用及機會
經過驗證的ML推理為智能合約開啟了新的設計空間。下面來看一些加密原生應用:
(1)DeFi
· 可驗證的鏈下ML預言機。繼續採用生成式AI可能有助於推動行業為內容實施簽名方案。簽名數據可隨時應用於ZK,使數據具有可組合性且可信。 ML模型可以對簽名數據進行鏈下處理以進行預測和分類(例如,對選舉結果或天氣事件進行分類)。這些鏈下ML預言機可以通過驗證推理並在鏈上發布證明,以無需信任的方式解決現實世界的預測市場、保險協議合約等問題。
· ML參數化的DeFi應用。 DeFi有很多方面可以更加自動化。例如,借貸協議可以使用ML模型實時更新參數。今天的借貸協議主要信任由組織運行的鏈下模型來進行抵押品事宜、LTV、清算門檻等相關決策,但社區訓練的開源模型可能是更好的替代方案,這類模型可以由任何人運行和驗證。
· 自動交易策略。展示財務模型策略的回報狀況的一種常見方法是,MP向投資者提供各種回測。然而,在執行交易時,是沒有辦法驗證策略是否遵循了模型的——投資者必須相信策略確實遵循了模型。 zkML提供了一個解決方案,MP可以在進行特定位置部署時提供財務模型推理證明。這對於DeFi管理的金庫來說特別有用。
(2)安全性
· 智能合約的欺詐監控。 ML模型可以用來檢測潛在的惡意行為並暫停合約,而不依靠緩慢的人工治理或中心化主體來控制是否暫停合約。
(3)傳統ML
· Kaggle的去中心化、無需信任的實現。可以創建這樣一個協議或市場,允許MC或其他相關方在MP不披露模型權重的情況下驗證模型的準確性。這對於模型銷售、模型準確性競爭等會很有用。
· 生成式AI的去中心化prompt(提示)市場。生成式AI的prompt創建已經演變成一種複雜的工藝,最好的prompt輸出通常包含許多modifier修飾符。外部各方可能願意從創建者那裡購買這些複雜的prompt。 zkML可以在這裡發揮兩方面作用:1)驗證prompt輸出,以向潛在購買者確保prompt確實創建了所需的圖像;2)允許prompt所有者在prompt被購買後仍然保有prompt的所有權,對購買者匿名的同時仍然為他們生成經過驗證的圖像。
(5)身份驗證
· 用保護隱私的生物識別身份驗證取代私鑰。私鑰管理仍然是web3用戶體驗最大的摩擦之一。通過面部識別或其他獨特因素提取私鑰是zkML的一種可能的解決方案。
· 公平的空投和貢獻者獎勵。 ML模型可用於創建詳細的用戶角色,以根據多種因素確定空投分配或貢獻獎勵。當與身份解決方案結合使用時,這種功能會特別強大。在這種情況下,有種可能性是讓用戶運行一個開源模型來評估他們在應用程序中的參與度,以及更高層的生態參與度(比如治理論壇帖子),以推斷他們的分配額度。然後,他們向合約提供此證明以接收代幣分配。
(6)Web3社交
· web3社交媒體過濾功能。 web3社交應用程序的去中心化性質將導致更多的垃圾郵件和惡意內容。理想情況下,社交媒體平台可以使用社區同意的開源ML模型,並在選擇過濾帖子時發布模型推理的證明。
· 廣告/推薦。作為一個社交媒體用戶,我可能願意看到個性化的廣告,但希望對廣告商保密我的偏好和興趣。我可以選擇根據我的喜好在本地運行一個模型,該模型向媒體應用程序提供信息,然後展示我想要的內容。在這種情況下,廣告商可能願意為終端用戶付費,但這些模型可能遠沒有當前的目標廣告模型那麼複雜。
(7)創作者經濟/遊戲
· 遊戲內經濟再平衡。 ML模型可用於動態調整代幣的發行、供應、銷毀、投票閾值等。一種可能的模式是,如果達到一定的再平衡閾值,並且推理證明得到驗證,那麼合約就可能受激勵以重新平衡遊戲內經濟。
· 新型鏈上游戲。可以創建人類對抗AI的合作遊戲和其他創新的鏈上游戲,此時無需信任的AI模型充當非玩家(NPC)角色。 NPC採取的每一個行動都會被發佈到鏈上,並帶有一個證明,任何人都可以驗證該證明以確定運行模型的正確性。在Modulus Labs的Leela vs. the World案例中,驗證者希望確保正在下棋的是1900 ELO AI,而非棋手Magnus Carlson。另一個例子是AI Arena,這是一款Super Smash Brothers風格的AI戰鬥遊戲。高風險競爭環境中的玩家希望確保他們訓練的模型不受干擾或者不會出現作弊行為。
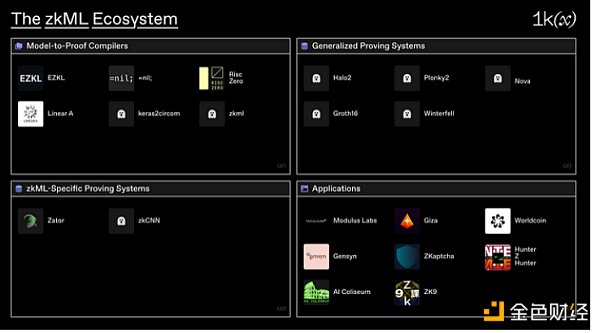
4、新興項目和基礎設施
zkML的生態系統可以大致分為四大類:
· Model-to-Proof Compilers(模型到證明編譯器):將模型從現有格式(例如Pytorch、ONNX等)編譯成可驗證計算電路的基礎設施。
· 通用證明系統:用來驗證任意計算軌蹟的證明系統。
· 特定zkML證明系統:專門用於驗證ML模型的計算軌蹟的證明系統。
· 應用程序:處理獨特zkML用例的項目。
(1)Model-to-Proof Compilers(模型到證明編譯器)
在研究zkML生態系統時,大多數注意力都集中在模型到證明編譯器上。通常,這些編譯器會將使用Pytorch、Tensorflow或類似語言編寫的高級ML模型轉換為ZK電路。
EZKL是一個庫和命令行工具,用於在zk-SNARK中對深度學習模型進行推理。使用EZKL,你可以在Pytorch或TensorFlow中定義計算圖,將其導出為ONNX文件,一些樣本輸入包含在JSON文件中,並將EZKL指向這些文件以生成zkSNARK電路。隨著最新的性能改進,EZKL現在可以在大約6秒內佔用1.1GB RAM證明一個MNIST大小的模型。到目前為止,EZKL已經有一些重要的早期採用,被用作各種黑客馬拉松項目的基礎設施。
Cathy So的circomlib-ml庫包含Circom的各種ML電路模板。電路包含一些最常見的ML功能。同樣由Cathie開發的Keras2circom是一個python工具,它使用底層circomlib-ml庫將Keras模型轉換為Circom電路。
LinearA為zkML開發了兩個框架:Tachikoma和Uchikoma。 Tachikoma用於將神經網絡轉換為純整數形式並生成計算軌跡。 Uchikoma是一個將TVM的中間表示轉換為不支持浮點運算的編程語言的工具。 LinearA計劃支持Circom和Solidity,前者使用域算法,後者使用有符號和無符號整數算法。
Daniel Kang的zkml是一個用於在ZK-SNARKs中構建ML模型執行證明的框架。在撰寫本文時,它能夠證明一個使用大約5GB內存運行約16秒的MNIST電路。
更通用的模型到證明編譯器還有Nil Foundation和Risc Zero。 Nil Foundation的zkLLVM是一個基於LLVM的電路編譯器,能夠驗證使用流行編程語言(如C++、Rust和JavaScript/TypeScript等)編寫的計算模型。與本文提到的其他一些模型到證明編譯器相比,它是通用的基礎設施,但仍然適用於像zkML這樣的複雜計算。當與證明市場相結合時,該功能將格外強大。
Risc Zero面向RISC-V開原指令集構建了一個通用的zkVM,因此支持現有的成熟語言,如C++和Rust,以及LLVM工具鏈。這將支持主機和客戶端zkVM代碼之間的無縫集成,類似於Nvidia的CUDA C++工具鏈,但使用了ZKP引擎代替GPU。與Nil類似,可以使用Risc Zero來驗證ML模型的計算軌跡。
(2)通用證明系統
證明系統的改進是zkML實現的主要推動力,特別是custom gates(自定義門)和lookup tables(查找表)的引入。這主要是由於ML對非線性的依賴。簡而言之,非線性是通過激活函數(例如ReLU、sigmoid和tanh)引入的,這些函數應用於神經網絡內線性變換的輸出。由於受數學運算門的限制,在ZK電路中這些非線性實現是有難度的。 Bitwise decomposition(逐位分解)和lookup tables(查找表)可以通過將非線性的可能結果預先計算到查找表中來幫助解決這個問題,有趣的是,這在ZK中計算效率更高。
由於這個原因,Plonkish證明系統往往是zkML最流行的後端。 Halo2和Plonky2的table-style(表式)算法方案可以通過lookup參數很好地處理神經網絡非線性。此外,Halo2有一個充滿活力的開發者工俱生態系統,再加上它非常靈活,使其成為包括EZKL在內的很多項目名副其實的後端支柱。
其他證明系統也有自己的優點。基於R1CS的證明系統包括用於小型證明的Groth16和處理超大電路和線性時間證明器的Gemini。如Winterfell證明者/驗證者庫這樣的基於STARK的系統也非常有用,特別是當通過Giza的工具實現時,Giza工具將Cairo程序的軌跡作為輸入值,並使用Winterfell生成STARK證明來證明輸出值的正確性。
(3)特定zkML證明系統
在有效的證明系統設計方面已經取得了一些進展,這些系統可以處理複雜的、電路不友好的高級ML模型操作。 Modulus Labs的基準報告證明,像zkCNN這樣基於GKR證明系統的系統,或者像Zator這樣使用複合技術的系統,通常比通用的同類系統性能更高。
zkCNN是一種使用零知識證明來證明卷積神經網絡(convolutional neural networks)正確性的方法。它使用sumcheck協議來證明快速傅里葉(Fourier)變換和卷積,其線性證明時間比漸近計算結果更快。交互式證明引入了若干改進和通則,包括驗證卷積層、ReLU激活函數和最大池化。 zkCNN特別有趣,因為Modulus Labs的基準報告發現,zkCNN在證明生成速度和RAM消耗方面都優於其他通用證明系統。
Zator是一個旨在探索使用遞歸SNARKs來驗證深度神經網絡的項目。目前驗證深層模型的約束條件是將整個計算軌跡擬合到單個電路中。 Zator提出使用遞歸SNARKs一次驗證一層,可以漸進增量驗證N步重複計算。他們使用Nova將N個計算實例縮減到一個實例中,這個實例可以通過單個步驟進行驗證。通過這種方法,Zator能夠snark一個具有512層的網絡,這與當今大多數生產式AI模型一樣深。對於主流用例來說,Zator的證明生成和驗證時間仍然太長,但是其複合技術還是很有趣的。
(4)應用程序
鑑於zkML仍處於早期階段,它將大部分重心都放在了上述基礎設施方面。然而,目前有一些項目正在進行應用開發。
Modulus Labs是zkML領域中最多樣化的項目之一,致力於應用範例和相關研究。在應用方面,Modulus Labs通過RockyBot(鏈上交易機器人)和Leela vs. the World(一種國際象棋遊戲,所有人與經驗證的Leela國際象棋引擎實例對決)展示了zkML的用例。該團隊還涉足研究領域,撰寫了The Cost of Intelligence(智能的成本)一文,對不同大小模型的各種驗證系統的速度和效率進行了基準測試。
Worldcoin正在應用zkML,試圖建立一個保護隱私的人格證明協議。 Worldcoin正在使用定制硬件來處理高分辨率虹膜掃描,這些掃描被插入到他們的Semaphore實現中。然後,可用於執行有用的操作,如成員資格認證和投票。他們目前使用具有安全enclave的可信運行環境來驗證攝像頭簽名的虹膜掃描,但他們最終的目標是使用ZKP來證明神經網絡對加密級別安全保障的正確推理。
Giza是一種可以以一種完全無需信任的方法在鏈上部署AI模型的協議。它使用的技術棧包括用於表示機器學習模型的ONNX格式,用於將這些模型轉換為Cairo程序格式的Giza Transpiler,用於以可驗證和確定性的方式執行模型的ONNX Cairo Runtime,以及用於部署和執行鏈上模型的Giza Model智能合約。雖然Giza也可以屬於模型到證明的編譯器類別,但它們定位為ML模型市場是當今更有趣的應用之一。
Gensyn是一個去中心化硬件供應網絡,用於訓練ML模型。具體來說,他們正在設計一個基於梯度下降算法的概率審計系統,並使用模型檢查點使去中心化的GPU網絡能夠為大規模模型訓練提供服務。雖然他們的zkML應用明顯特定於自身用例——他們希望確保當節點下載和訓練模型的一部分時,他們對模型的更新是誠實的——但卻展示了ZK和ML結合的強大功能。
ZKaptcha專注於web3的bot問題,為智能合約提供captcha(驗證碼)服務。它們目前的實現是讓終端用戶通過完成captcha來生成人類工作的證明,captcha由鏈上驗證者驗證,並通過幾行代碼由智能合約訪問。今天,它們主要只依賴於ZK,但計劃在未來實現zkML,類似於現有的web2 captcha服務,分析鼠標移動等行為,以確定用戶是否是人類。
zkML市場仍處於相當早期的階段,但很多應用程序已經進行了黑客馬拉松級別的試驗。這些項目包括AI Coliseum(一個使用ZK證明來驗證機器學習輸出的鏈上AI競賽)、Hunter z Hunter(一個使用EZKL庫來驗證帶有halo2電路的圖像分類模型輸出的照片尋寶遊戲),以及zk Section 9(它將AI圖像生成模型轉換為用於鑄造和驗證AI藝術的電路)。
5、zkML面臨的挑戰
雖然zkML正在以光速進行改進和優化,但該領域仍然存在一些核心挑戰。這些挑戰涉及到技術和實踐方面,具體如下:
· 高精度的量化
· 電路的大小(特別是多層網絡)
· 矩陣乘法的有效證明
· 對抗攻擊
量化是將大多數ML模型用來表示模型參數和激活函數的浮點數表示為定點數的過程,這在處理ZK電路的域算法時是必不可少的。量化對機器學習模型精度的影響取決於所使用的精度水平。通常,使用較低的精度(即更少的bits)會導致準確性降低,因為它會應用四捨五入和近似誤差。然而,有幾種技術可以用來最小化量化對準確性的影響,例如在量化之後微調模型,以及使用量化感知訓練等技術。此外,zkSummit 9上的一個黑客馬拉松項目Zero Gravity已表明,為邊緣設備開發的替代神經網絡架構(如無權重神經網絡)可用於避免電路量化的問題。
除了量化,硬件是另一個關鍵挑戰。一旦機器學習模型通過電路進行了正確表示,由於ZK的簡潔性,驗證其推論的證明既便宜又快速。這裡的挑戰不在於驗證者,而是在於證明者,因為隨著模型越來越大,RAM消耗和證明生成時間會迅速增加。某些證明系統(例如使用sumcheck協議和分層算法電路的基於GKR的系統)或複合技術(例如wrapping Plonky2,它有高效的證明時間,但在較大模型的有效證明大小方面表現很差,使用Groth16,它不會隨著模型的複雜性加大而增加證明大小)更適合處理這些問題,但是管理權衡是構建zkML項目的核心挑戰。
在對抗方面,還有工作要做。首先,如果一個無需信任的協議或DAO選擇實現一個模型,在訓練階段仍然存在對抗攻擊的風險(例如,訓練一個模型在看到一個可用於操縱後續推理的輸入時表現出特定的行為方式)。聯邦學習(federated learning)技術和訓練階段zkML可能是最小化這種攻擊面的一種方法。
另一個核心挑戰是,當一個模型屬於隱私保護模型時,存在模型竊取攻擊的風險。雖然模型的權重可以被混淆,但理論上仍可以在有足夠的輸入-輸出對的情況下對權重進行反向工程。雖然這種風險主要針對小型模型,但風險就是風險。
6、擴展智能合約
儘管優化這些模型以符合ZK運行條件還存在著這樣那樣的挑戰,但優化改進正在以指數級的速度進行,有人預計,假設在進一步的硬件加速條件下,我們將很快擴展更廣泛的機器學習領域。 zkML已經從2021年0xPARC的zk-MNIST演示(展示瞭如何在可驗證的電路中執行小型MNIST圖像分類模型),發展到Daniel Kang在不到一年後對ImageNet-scale模型做了同樣的驗證。 2022年4月,ImageNet-scale模型的準確率從79%進一步提高到92%,儘管目前的驗證時間較慢,但像GPT-2這樣大的網絡在短期內是可行的。
我們認為zkML是一個豐富且不斷發展的生態系統,它希望擴展區塊鍊和智能合約的功能,使其更加靈活、適應性更強、更加智能。
雖然zkML仍處於早期開發階段,但它已經開始顯示出光明前景。隨著技術的發展和成熟,我們有望看到出現更多鏈上zkML的創新用例。