作者:J1N,Techub News
引言:Epoch One to Two
Kuzco 是一個專門服務LLM 大語言模型算力挖礦網絡,今年入選a16z 於9 月9 日在紐約啟動的Crypto Startup Accelerator(CSX)秋季加速器計劃,被該計劃選中的項目將能獲得a16z 至少50 萬美元的投資,並將得到a16z 營運團隊的指導和支持。目前該加速器計劃已結束。
11 月16 日, Kuzco 宣布,第一期(Epoch One)激勵計劃將於2024 年11 月18 日結束,所有操作將暫停,數據快照將永久存儲,最終積分排名會公佈在新排行榜上。
官方披露,Epoch One 從2024 年3 月6 日推出,峰值設備數量超過8000 台,該網絡上運行 Meta 發布的8B 規格的Llama-3 AI 大語言模型,共計推理超過1 萬億條tokens。
並宣佈在接下來的幾週內公佈融資資訊和專案發展路線圖,以及第二期(Epoch Two)激勵計畫將於12 月9 日開啟, Epoch Two 將帶來一些新特性,如更高的NVIDIA硬體的吞吐量與可靠性;鼓勵使用者連接到頂尖算力設備如A100 和H100;支援更多的影像生成和多模態語言模型VLM。
目前離Epoch Two 開啟還有半個月的準備時間,本文將探討:
-
分享個人挖礦的實踐與成果,從單機到集群的轉變。
-
展示透過研究和實踐獲取融資,並建立高規格機器的整個過程。
-
探討硬體配置與專案需求的匹配性,並解答投資人常見疑問。
Epoch One 回顧:單兵作戰
配置
筆者的配置清單包括RTX 系列顯示卡2060、2070S、3080、4060、4060Ti,以及4 張4070S 和2 台蘋果M2、M3 設備。這些設備分佈在幾台主機、筆記型電腦以及一台專用礦機上。
成本
值得一提的是,這些顯示卡原本就是筆者以往每年按遊戲需求購置的,並非專為挖礦購買。因此,計算成本時並未將硬體購置費用計入,僅統計礦機的實際電費成本。這裡拿第一篇《 a16z「門徒」Kuzco 實操指南:如何有效率地進行AI 算力挖礦? 》組裝的礦機舉例。
該礦機配置:
-
主機板:z490(後續換工業板)
-
CPU:10 代I9
-
顯示卡:2060、2070s、3080、4060ti、4070s
手搓礦機
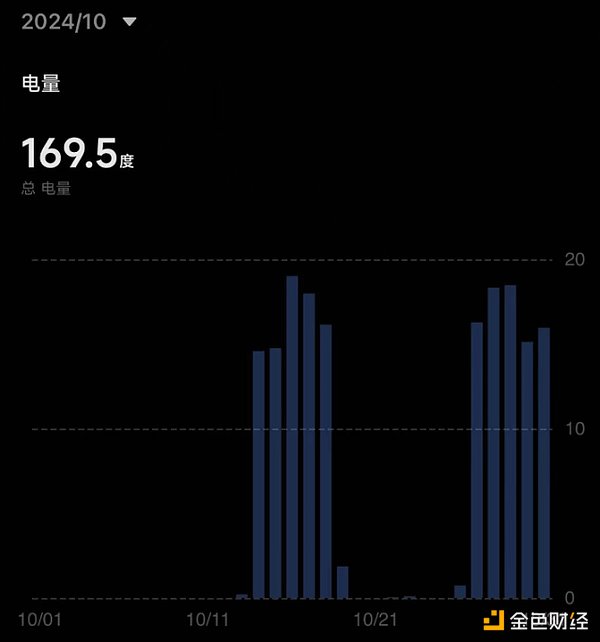
下圖為該礦機10 月和11 月消耗的電量,總共是564 度,獲得積分(KZO Point)約為6 億分。所有的機器加起來約為11 億分。具體的電費成本需根據各位所在地的電費情況計算,這裡僅提供參考。
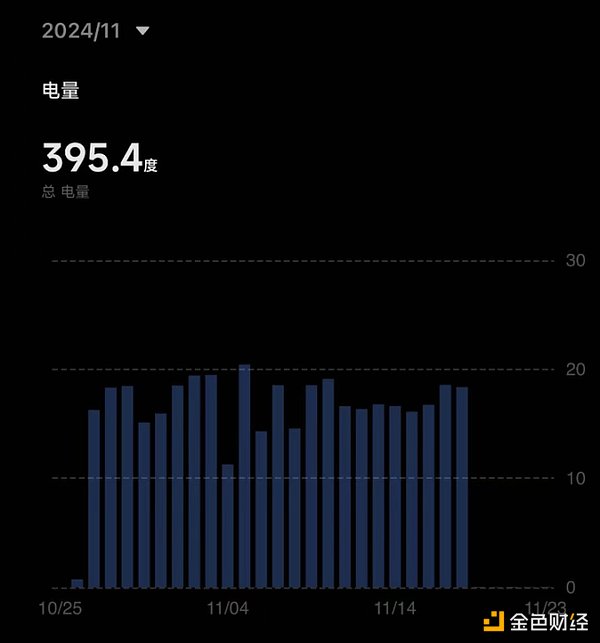
圖最右,共獲得10 億積分
籌備Epoch Two:集群部署
基於筆者在第一篇文章中的分享,以及親身參與設備組裝、調試和環境部署的豐富運維經驗,筆者成功爭取到一定資金支持,並將其全部投入用於組裝高性能礦機,以進一步提升算力規模和營運效率。

單兵手搓到集群部署
高規格機器的配置與選擇邏輯
結合筆者在Epoch One 的實務經驗,對主機板、CPU、顯示卡、電源、平台以及網路配置進行了全面優化,選擇了更適配的硬體組合,不僅提升了整體運作的穩定性、安全性和效率,在硬體選擇上也更注重二手市場的流通性。此策略能夠有效降低的實際投入成本,為後續參與者提供更高的性價比選擇。

主機板
筆者選擇工業主機板而非主流的B85,主要基於性能、穩定性和性價比的綜合考量。
效能方面,執行Kuzco 的Llama-3 模型需要啟動多個Docker 進程,而並行運行這些進程會佔用大量CPU 資源,對CPU 的效能要求較高,而B85 相容的CPU 無法滿足此需求。
此外,工業主機板在長時間穩定運作、耐高溫性能以及廠商保固方面具備明顯優勢,同時在二手市場上的流通性更強,因此無疑是最優選擇。
顯示卡
筆者選擇使用4070S 作為主力顯示卡,主要基於以下幾點:
AI 運算效能的優點:相較於30 系顯示卡,40 系顯示卡在AI 運算中的效能提升遠大於在遊戲效能上的提升。其核心原因在於AI 算力主要依賴顯示卡的CUDA 核心數量,而40 系列顯示卡的CUDA 核心顯著多於30 系列顯示卡。
能源效率比優勢:筆者對多款GPU 進行了詳細測試,計算了每個Tokens 的平均功耗
-
4060Ti(160W):0.125 Tokens/W
-
3080(330W):0.22 Tokens/W
-
4090(450W):0.26 Tokens/W
-
4070S(220W):0.38 Tokens/W
從測試結果來看,4070S 在性能與功耗的平衡上表現最佳,其更高的能源效率比直接降低了電費成本,使其成為性價比最高的選擇。
二手市場的價格和流動性:作為中高階顯示卡,4070S 在二手市場具備較高的流動性和保值性,進一步降低了設備的持有成本,同時為後續的硬體升級提供了靈活性。
CPU
如前文所述,Kuzco 的Llama-3 在運行時需要啟動多個Docker,這對CPU 資源的佔用極為顯著,尤其是在多卡運行的情況下,CPU 佔用率可能高達80%-90%。因此,多核心多執行緒的處理能力顯得格外重要。高效能、多執行緒、穩定的CPU 不僅能夠有效支援多任務運行,還能確保整個挖礦過程的穩定性和效率。

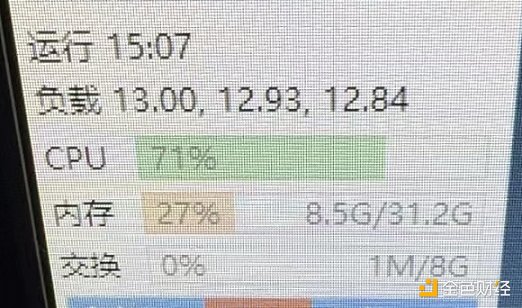
13 代i5 滿載跑顯卡能去到70%+ 佔用率
網路環境

軟路由為圖中方塊盒子
網路環境在挖礦中同樣至關重要,即使配置了高效能顯示卡,如果網路未最佳化,算力也會受到嚴重影響。根據筆者實測,網速不足可能導致算力下降至30%,而低品質的網絡節點則可能直接導致無法連接至Kuzco 網絡,這兩點對挖礦而言都是不可接受的。為了解決這些問題,筆者採用軟路由方案,這種方式不僅便於配置,而且在完成設定後幾乎無需人工幹預即可高效運行,理論上還能夠支援無限台設備的接入。至於具體的操作方式,建議讀者依需求自行查閱相關資料。
電源

經典長城2000w 核彈電源
在選擇電源時需要特別注意峰值功耗的問題,這也是為什麼即使7 張4070S 的額定功耗僅為1540W,筆者仍然選擇使用雙2000W 電源,總功率達到4000W。這並不是浪費資源,而是出於對設備運作穩定性和安全性的考量。
顯示卡在運作中會出現峰值功耗,即在某些瞬間其實際功耗可能達到額定功耗的1.5 倍甚至更多,隨後再回落到正常水平。如果電源功率不足以應對這種峰值,可能觸發電源的強制停機機制,甚至導致顯示卡損壞。這對礦機的正常運作是致命的威脅。
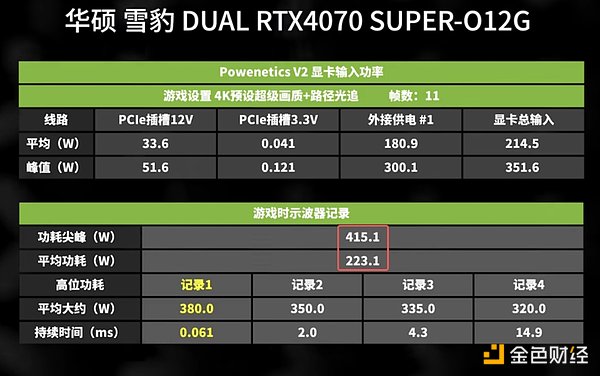
4070s 運轉功耗表現
以4070S 為例,雖然其額定功耗為220W,但峰值功耗可能超過400W。 7 張顯示卡的峰值功耗合計可能達到3000W 以上,因此配置雙2000W 電源供應器是為了確保機器的穩定運作。對於配置多張4090 的用戶尤其需要注意,單張4090 的額定功耗為450W,而峰值功耗可能高達770W。多卡情況下,僅靠兩個電源可能無法滿足需求,此時通常需要三台電源來確保系統穩定。
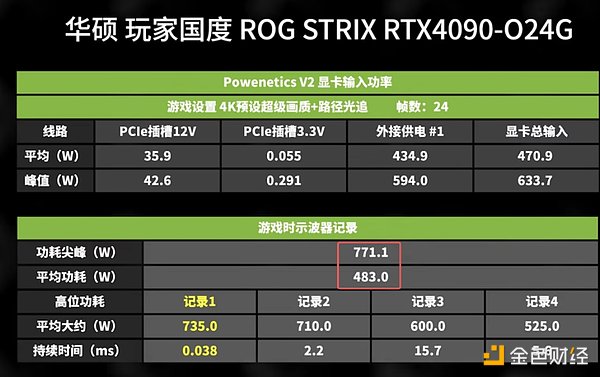
4090 運轉功耗表現
補充
至於BIOS 設定、硬體相容性以及遠端管理等問題,筆者在此不作過多展開。這些內容在網路上已有大量免費教學供參考,按照教學操作即可解決大多數問題。建議依照自己的硬體配置和需求進行針對性查閱和處理,簡單且有效率。
風險與效益
回答大家最關心的問題:每天能挖多少錢?坦白說,這個問題沒有明確的答案,因為風險與收益始終是並存的。我可以分享一個明確的觀點:無論是幣圈還是傳統行業,任何一個項目如果能夠精確計算出每天的收益,那麼你進去很可能已經賺不到大錢了。除非你擁有某些壟斷性資源,例如極低的電費成本或非常便宜的礦機設備,這樣才能在收益上佔優勢。然而,這樣的資源並非每個人都具備。
筆者選擇流動性好的設備,正是為了降低投資風險和成本壓力。以Kuzco 挖礦為例,成本主要集中在硬體的折舊和電費上,因此你的最大虧損也僅限於這些固定成本。如果不是在低成本的前提下參與,那麼任何投資決策都失去了意義。需要強調的是,挖頭礦的特性決定了沒有明確的收益預期,但這也正是頭礦的潛力所在。
從主觀判斷來看,這個賽道有著巨大的市場前景:一方面,Kuzco 獲得了a16z 的投資支援;另一方面,LLM 大型語言模型的需求正在快速擴大。想想看,幾乎沒有人會不用LLM 吧?像OpenAI 的ChatGPT、Meta 的Llama、以及馬斯克的XAI,這些平台一輪接一輪的高額融資,清楚地表明了這個行業的成長潛力。
對一般人來說,直接參與AI 產業並非易事。一方面,AI 技術門檻高;另一方面,AI 模型的訓練需要耗費鉅量的資源和經費,絕大多數人難以承受這樣的成本。而透過Kuzco 加入AI 算力網絡,一般人可以在成本可控的前提下,輕鬆參與這個高成長領域,為AI 算力貢獻一份力,同時獲得收益。
另外,比特幣價格目前即將突破10 萬美元,從2022 年的16,000 美元漲到如今的高點,背後有巨大的回撤風險。如果選擇直接購買AI 專案的代幣,也會面臨類似的高波動風險。相較之下,參與AI 算力網路是更穩健的選擇:不僅成本明確可控,還能以相對低的風險切入AI 產業的高速成長軌道。這是在當前環境下,一般人進入AI 領域實際可行的方式之一。